Latest

KI-Agenten übertreffen menschliche Hackerteams in ...
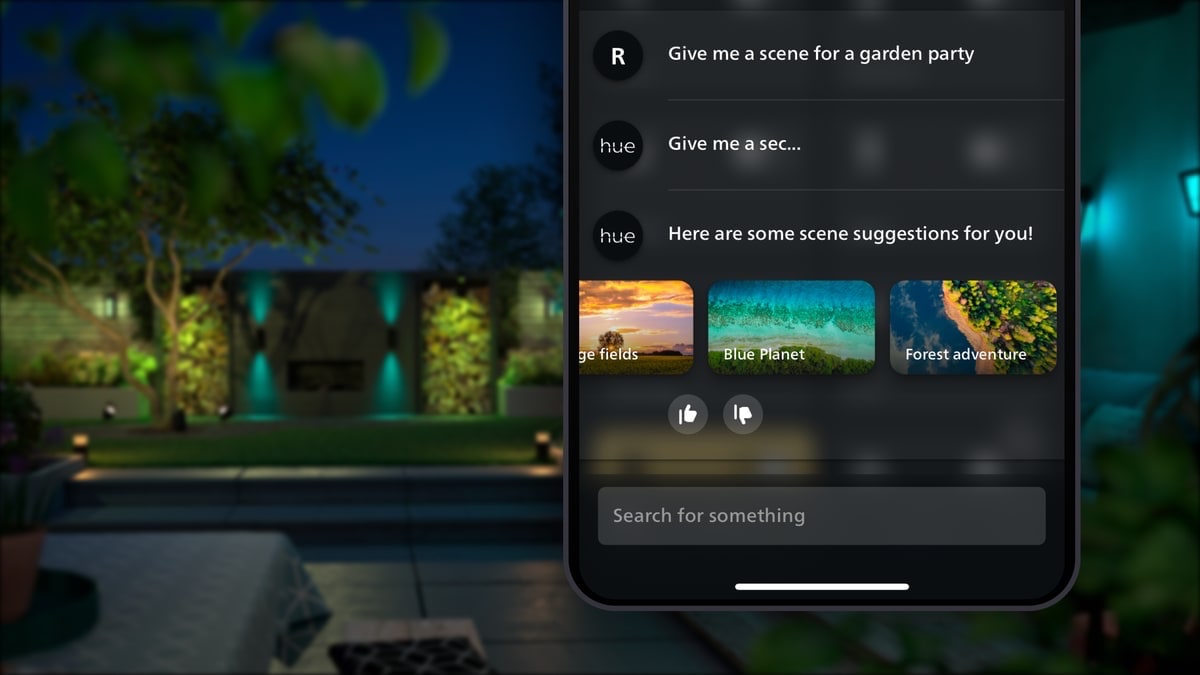
Philips Hue mit KI-Assistant startet
 1 year ago
23
1 year ago
23

Netflix zeigt neue Trailer für Knives Out 3 und de...
1 year ago
24

Exclusive: Microsoft's hybrid AI vision

Stranger Things Staffel 5: Start im November
1 year ago
24

Sakana AI stellt KI-Agenten vor, die sich selbst v...

Energiepreise in Deutschland: Sorge ist weiterhin ...
1 year ago
23

heise+ | Kaufberatung: Wie Sie die richtige Smartw...

Kioxia Exceria Plus G2 Portable: Kurz angeschaut
1 year ago
23

heise+ | Praxis "Digitaler Garten": So lassen Sie ...

Amazon Prime Video, Disney+, Netflix, Paramount+ u...
1 year ago
22

Immer wieder sonntags KW 22: Apple plant Software-...
1 year ago
22

IAEA meldet Anstieg iranischer Uranvorräte

Russische Nuklearanlagen durch Datenleck enttarnt

Die neue Reolink Altas ausprobiert
1 year ago
18

LexisNexis meldet Datenleck

Schufa: Umfrage zeigt gefährliche Ausmaße von Onli...
1 year ago
18

ObsIdentify: Kostenlose KI-App macht Naturbestimmu...
1 year ago
18
Popular

Beelink ME Pro: Modularer Mini-PC und NAS-Hybrid startet bal...
5 months ago
144

E-Scooter: Neue Regeln bringen Blinkerpflicht und höhere Buß...
5 months ago
140

Beyond chatbots: How to build agentic AI systems
5 months ago
140

Bundesrat beschließt Lachgas-Gesetz
5 months ago
135

Gemini Robotics: Roboter-Durchbruch
1 year ago
132
 English (US) ·
English (US) · © DiekNews 2026. All rights are reserved