Latest
Anthropic nutzt Elevenlabs für die Sprachausgabe v...

EcoFlow Stream: Ausgefuchstes Balkonkraftwerk ausp...
 1 year ago
18
1 year ago
18

Anthropic verdreifacht Umsatz auf drei Milliarden ...

Öffentlicher Personennahverkehr (ÖPNV): Nutzen lau...
1 year ago
22

Pi-hole 6.1: Umfangreiches Update des DNS-Werbeblo...
1 year ago
24

Google Veo 3: Nutzer generieren innerhalb von Tage...

„Blades of Fire“ im Test: MercurySteam wünscht sic...
1 year ago
23

Richter prüft Einschränkungen für Googles KI-Strat...

OpenAI will ChatGPT zu einem "intuitiven KI-Super-...

Twitch: Neue (geplante) Funktionen
1 year ago
24

Auswertung Umfrage Mai 2025: Tempolimit auf Autoba...
1 year ago
23
Elevenlabs stellt neue KI-Sprach-Agenten vor
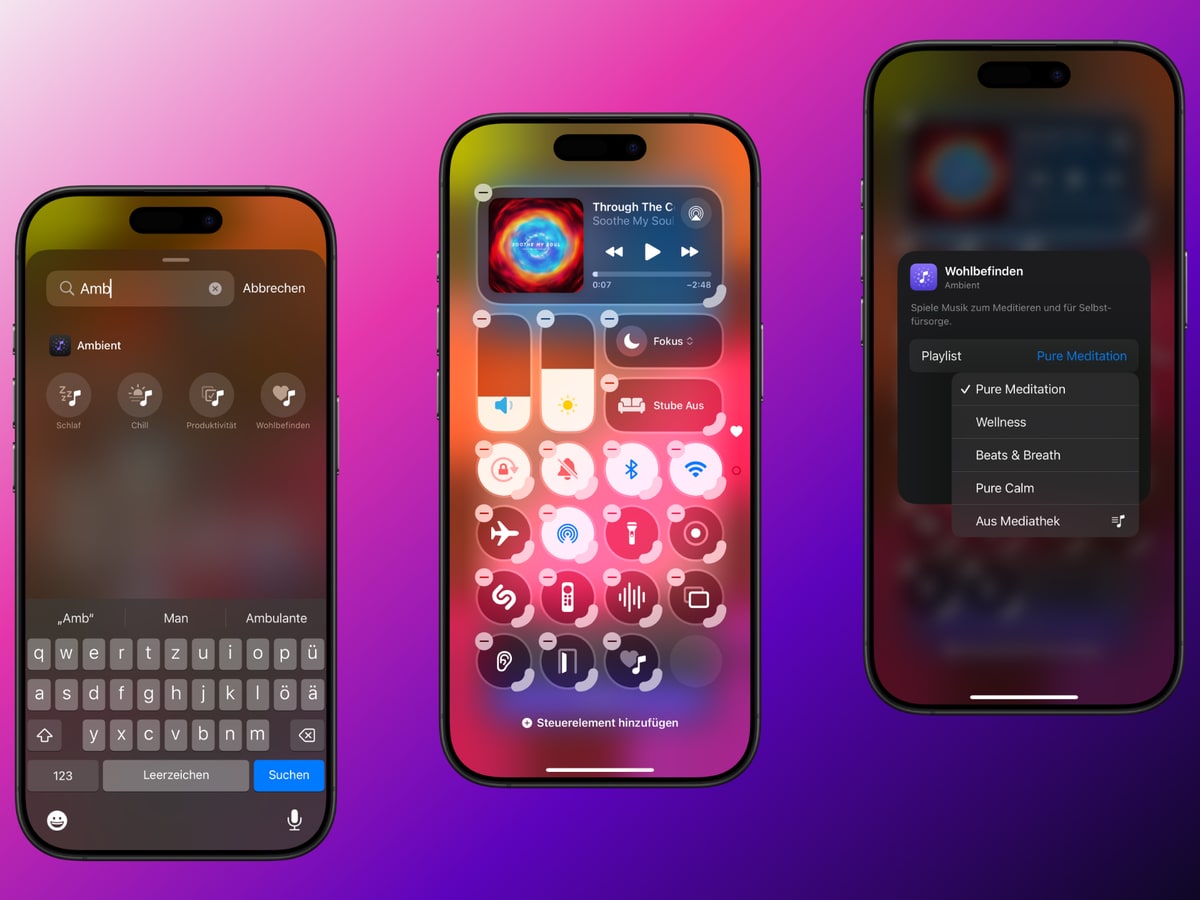
iPhone: Schnell auf Ambient-Playlisten zugreifen
1 year ago
24

Whoop 5.0 MG im Test: Mehr Daten, mehr Gesundheit ...
1 year ago
23

YouTube Premium Lite: Werbung in Shorts ab Ende Ju...
1 year ago
24

Windows 11: Praktischer Tastatur-Shortcut für bess...
1 year ago
25

Neues Tool erstellt KI-Profile aus YouTube-Komment...

UGREEN NAS: Firmware-Update 1.5.0.2628 bringt Neue...
1 year ago
24
Popular

Beelink ME Pro: Modularer Mini-PC und NAS-Hybrid startet bal...
5 months ago
144

E-Scooter: Neue Regeln bringen Blinkerpflicht und höhere Buß...
5 months ago
140

Beyond chatbots: How to build agentic AI systems
5 months ago
140

Bundesrat beschließt Lachgas-Gesetz
5 months ago
135

Gemini Robotics: Roboter-Durchbruch
1 year ago
132
 English (US) ·
English (US) · © DiekNews 2026. All rights are reserved