Eine neue Studie zeigt eine fundamentale Schwäche aktueller KI-Systeme. Selbst die leistungsstärksten multimodalen Sprachmodelle versagen bei grundlegenden visuellen Aufgaben, die Kleinkinder mühelos bewältigen.
Während multimodale KI-Modelle bei Expertenwissen-Tests wie MMMU Ergebnisse von mehr als 90 Prozent erreichen, offenbart eine neue Studie von UniPat AI eine Lücke: Dieselben Systeme scheitern an visuellen Grundaufgaben, die Menschen bereits vor dem Spracherwerb beherrschen. Das beste getestete Modell, Gemini-3-Pro-Preview, erreicht laut der Studie nur 49,7 Prozent. Menschliche Erwachsene kommen auf 94,1 Prozent.
 Bei dieser Aufgabe zur feinkörnigen visuellen Wahrnehmung wählte Gemini-3-Pro-Preview die falsche Option D statt der korrekten Option B. Das Modell verbalisierte die Geometrie übermäßig und verfehlte die exakte Kontur. | Bild: Chen et al.
Bei dieser Aufgabe zur feinkörnigen visuellen Wahrnehmung wählte Gemini-3-Pro-Preview die falsche Option D statt der korrekten Option B. Das Modell verbalisierte die Geometrie übermäßig und verfehlte die exakte Kontur. | Bild: Chen et al.Forscher aus chinesischen Institutionen wie UniPat AI, Peking University, Alibaba Group und MoonShot AI entwickelten dafür den Benchmark „BabyVision" mit 388 Aufgaben in vier Kategorien. Diese testen Fähigkeiten, die Menschen laut entwicklungspsychologischer Forschung bereits in den ersten Lebensmonaten entwickeln: feinkörnige visuelle Unterscheidung (etwa das Erkennen subtiler Unterschiede zwischen ähnlichen Mustern), das Verfolgen von Linien durch Labyrinthe oder über Kreuzungen, räumliche Wahrnehmung (zum Beispiel das Zählen verdeckter 3D-Blöcke) sowie visuelle Mustererkennung bei Rotationen und Spiegelungen.
80 Kinder gegen sechs Frontier-Modelle
In einem Vergleichstest mit 80 Kindern verschiedener Altersgruppen zeigte sich das Ausmaß der Diskrepanz. Die meisten getesteten Frontier-Modelle lagen unter dem Durchschnitt dreijähriger Kinder. Nur Gemini3-Pro-Preview übertraf diese Gruppe konsistent, blieb aber etwa 20 Prozentpunkte hinter typischen Sechsjährigen zurück.
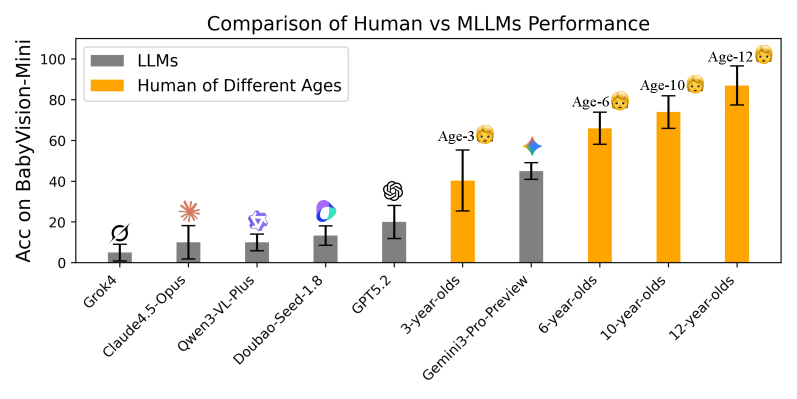 Die meisten KI-Modelle schneiden schlechter ab als dreijährige Kinder. Nur Gemini-3-Pro-Preview übertrifft die Dreijährigen, bleibt aber deutlich hinter Sechsjährigen zurück. | Bild: Chen et al.
Die meisten KI-Modelle schneiden schlechter ab als dreijährige Kinder. Nur Gemini-3-Pro-Preview übertrifft die Dreijährigen, bleibt aber deutlich hinter Sechsjährigen zurück. | Bild: Chen et al.Bei den proprietären Modellen folgen auf Gemini 3 Pro mit deutlichem Abstand GPT-5.2 mit 34,4 Prozent, Doubao-1.8 von Bytedance mit 30,2 Prozent und Claude 4.5 Opus mit nur 14,2 Prozent. Die Open-Source-Modelle schneiden noch schlechter ab. Das beste unter ihnen, Qwen3VL-235B-Thinking, erreicht nur 22,2 Prozent.
Besonders drastisch fallen die Ergebnisse bei einzelnen Aufgabentypen aus. Beim Zählen von 3D-Blöcken erreicht selbst das beste Modell nur 20,5 Prozent, während Menschen 100 Prozent schaffen. Bei der Aufgabe "Lines Observation", bei der Linien durch Kreuzungen verfolgt werden müssen, erreicht nur Gemini 83,3 Prozent. Die meisten anderen Modelle landen bei null Prozent.
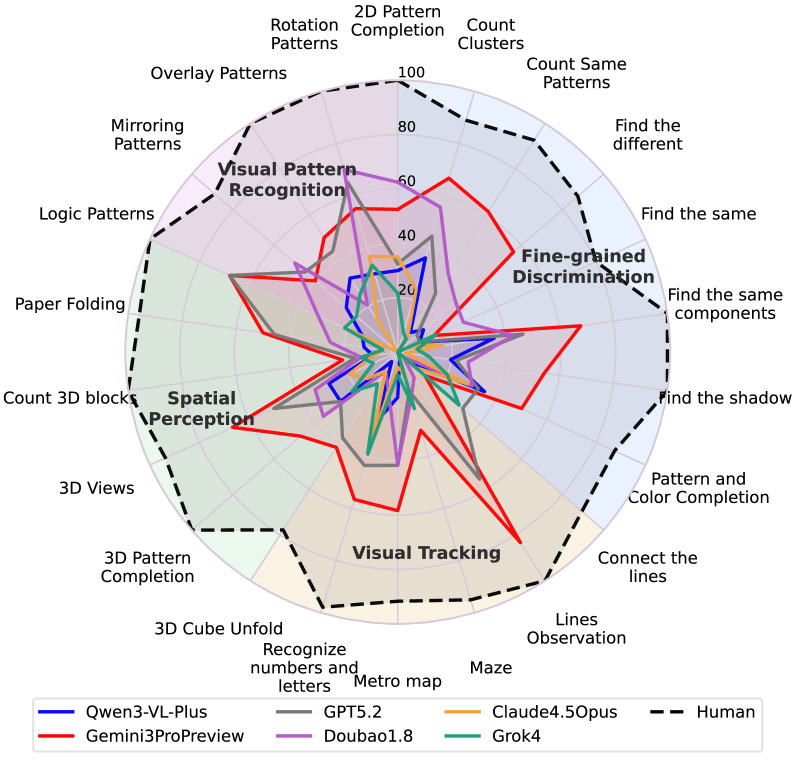 Die gestrichelte Linie zeigt die menschliche Leistung bei nahezu 100 Prozent in allen Kategorien. Alle KI-Modelle bleiben weit dahinter zurück, besonders bei Visual Tracking und räumlicher Wahrnehmung. | Bild: Chen et al.
Die gestrichelte Linie zeigt die menschliche Leistung bei nahezu 100 Prozent in allen Kategorien. Alle KI-Modelle bleiben weit dahinter zurück, besonders bei Visual Tracking und räumlicher Wahrnehmung. | Bild: Chen et al.Der Verbalisierungs-Flaschenhals als Ursache
Die Forscher führen alle Fehler auf ein gemeinsames Problem zurück, das sie als Verbalisierungs-Flaschenhals bezeichnen. Aktuelle multimodale Modelle übersetzen visuelle Eingaben zunächst in Sprachrepräsentationen, bevor sie darüber nachdenken. Visuelle Informationen, die sich nicht in Sprache ausdrücken lassen, gehen dabei verloren.
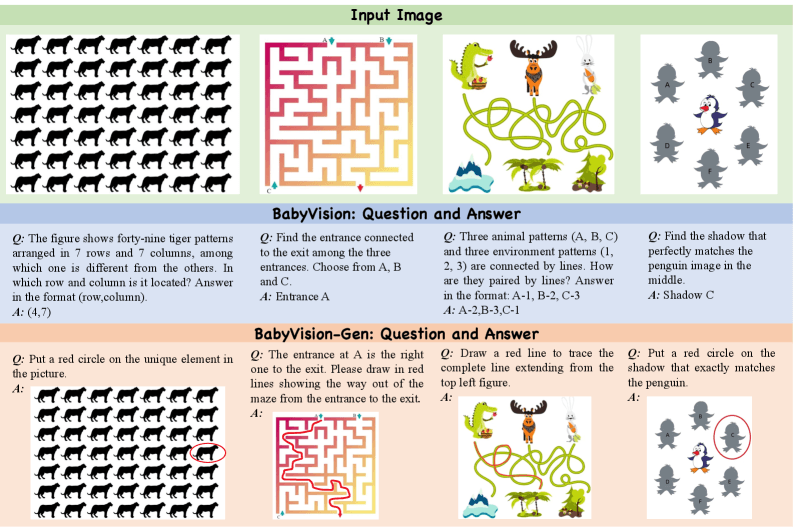 Beispielaufgaben aus dem BabyVision-Benchmark. Oben die Eingabebilder, in der Mitte die sprachbasierten Fragen und Antworten, unten die generativen Aufgaben von BabyVision-Gen, bei denen Modelle ihre Lösung durch Zeichnen zeigen sollen. | Bild: Chen et al.
Beispielaufgaben aus dem BabyVision-Benchmark. Oben die Eingabebilder, in der Mitte die sprachbasierten Fragen und Antworten, unten die generativen Aufgaben von BabyVision-Gen, bei denen Modelle ihre Lösung durch Zeichnen zeigen sollen. | Bild: Chen et al.Semantischer Inhalt wie "ein rotes Auto auf einer Straße" lässt sich gut in Sprache übersetzen. Geometrische Beziehungen hingegen widersetzen sich der Verbalisierung, denn die exakte Krümmung einer Grenze oder die präzise Position eines Schnittpunkts lassen sich nicht verlustfrei in Worte fassen. BabyVision zielt laut den Forschern gezielt auf diese nicht beschreibbaren visuellen Eigenschaften ab.
Labyrinth als Endgegner
Die Forscher entwickelten zusätzlich "BabyVision-Gen", eine Erweiterung mit 280 Fragen. Hier sollten Modelle ihre Lösungen durch Bildgenerierung zeigen, etwa durch das Einzeichnen von Pfaden oder das Markieren von Unterschieden. Menschen lösen solche Aufgaben oft durch Zeichnen statt durch Verbalisieren. Kinder externalisieren visuelles Reasoning durch Zeichnen, bevor sie Lösungen verbalisieren können.
Die getesteten Bildgeneratoren zeigen vielversprechende Ansätze. Nano Banana Pro erreicht 18,3 Prozent, GPT-Image-1.5 kommt auf 9,8 Prozent. Bei Aufgaben wie dem Finden von Unterschieden erreicht Nano Banana Pro immerhin 35,4 Prozent.
Allerdings scheitern alle Generatoren vollständig bei Labyrinth-Aufgaben und dem Verbinden von Linien. Diese Aufgaben erfordern kontinuierliche räumliche Kohärenz über längere Sequenzen, die aktuelle Architekturen nicht aufrechterhalten können.
Die Forscher sehen in sogenannten "Unified Multimodal Models", die visuelle Verarbeitung und Generierung nativ integrieren, einen möglichen Ausweg. Solche Architekturen könnten visuelle Repräsentationen während des gesamten Reasoning-Prozesses beibehalten, anstatt sie in einen sprachlichen Flaschenhals zu komprimieren. Der auf GitHub verfügbare BabyVision-Benchmark soll als diagnostisches Werkzeug dienen, um Fortschritte in Richtung echter visueller Intelligenz zu messen.
Auch der von François Chollet entwickelte ARC-AGI-3 Benchmark testet grundlegende kognitive Fähigkeiten wie Objektpermanenz und Kausalität. Bei den interaktiven Minispielen, in denen KI-Agenten Spielmechaniken selbst herausfinden müssen, erzielen aktuelle Systeme null Punkte, während Menschen die Aufgaben in wenigen Minuten lösen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.


