![]()
Es gibt ein neues bestes Mathemodell. OpenAIs GPT-5.2 Pro hat einen Rekord auf dem besonders anspruchsvollen FrontierMath-Benchmark aufgestellt, wie Epoch AI getestet hat. Das Modell erreichte 31 Prozent auf der schwierigsten Stufe (Tier 4), ein deutlicher Sprung gegenüber dem bisherigen Höchstwert von 19 Prozent durch Gemini 3 Pro. Epoch AI testete das Modell manuell über die ChatGPT-Webseite, da es API-Probleme gab.
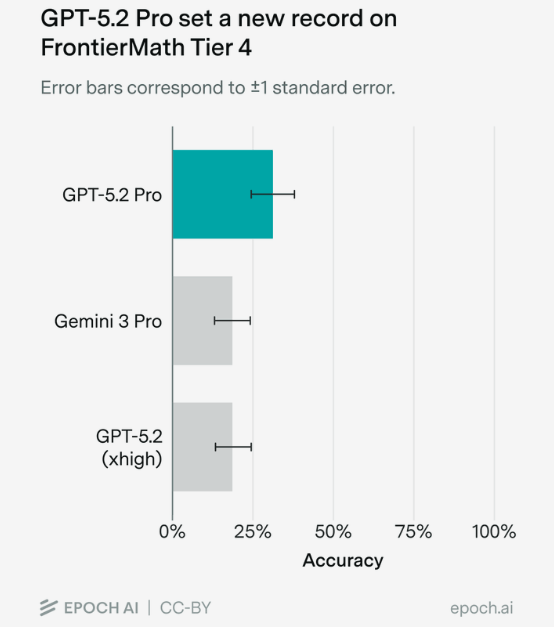 GPT-5.2 Pro erreicht 31 Prozent auf FrontierMath Tier 4, deutlich vor Gemini 3 Pro (19 Prozent) und GPT-5.2 xhigh (17 Prozent). | Bild: Epoch AI
GPT-5.2 Pro erreicht 31 Prozent auf FrontierMath Tier 4, deutlich vor Gemini 3 Pro (19 Prozent) und GPT-5.2 xhigh (17 Prozent). | Bild: Epoch AIVon 48 Aufgaben löste GPT-5.2 Pro 15, darunter vier, die zuvor noch kein Modell geschafft hatte. Mehrere Mathematiker bewerteten von dem KI-Modell entwickelte Lösungen überwiegend positiv, wobei einige auch Schwächen wie fehlende Strenge oder unbeabsichtigte Abkürzungen anmerkten.
Das Testergebnis bestätigt zuletzt positive Berichte über KI-Modelle, insbesondere GPT-5-Thinking und -Pro, als substanzielle Hilfe bei der Lösung mathematischer Aufgaben. Erdős-Probleme soll GPT-5 sogar autonom gelöst haben, bei anderen fungierte es als Hilfe. Der bekannte Mathematiker Terence Tao warnt dennoch vor voreiligen Schlüssen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.


