Der WorldVQA-Benchmark testet, ob multimodale Sprachmodelle visuelle Entitäten tatsächlich erkennen oder nur halluzinieren. Selbst die besten Modelle scheitern an der 50-Prozent-Marke.
Das Forschungsteam von Moonshot AI, dem Unternehmen hinter der KI-Modellreihe Kimi, hat mit WorldVQA einen neuen Benchmark veröffentlicht. Der Datensatz umfasst 3.500 Bild-Frage-Paare in neun Kategorien, von Natur und Architektur über Kultur und Kunst bis zu Marken, Sport und bekannten Persönlichkeiten.
"Hund" reicht nicht
WorldVQA unterscheidet sich von bestehenden Benchmarks wie MMMU oder MMBench dadurch, dass der Test die reine Objekterkennung strikt vom logischen Schlussfolgern trennt. Laut dem begleitenden Paper soll damit gemessen werden, "an was sich das Modell tatsächlich erinnert", und nicht, wie gut es kombinieren oder ableiten kann.
Die Fragen verlangen dabei spezifische Antworten. Wer etwa ein Bild eines Bichon Frisé mit "Hund" beantwortet, gilt als falsch, denn das Modell soll die konkrete Rasse erkennen.
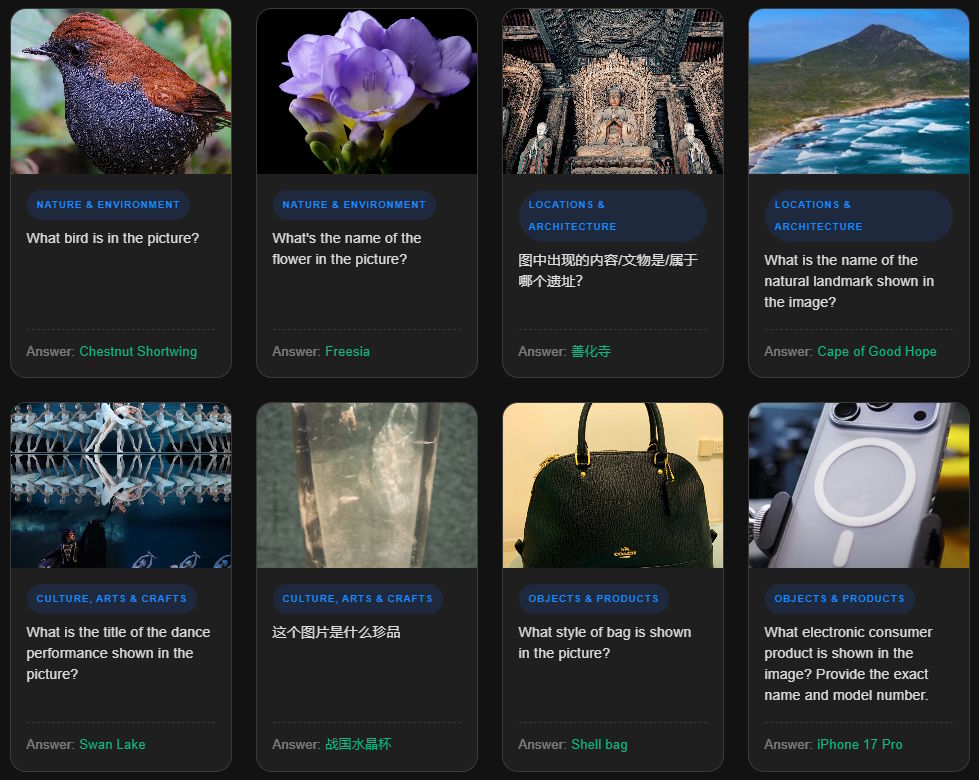 Die Testfragen des Benchmarks verlangen hochspezifische Antworten, wie die exakte Vogelart oder Produktbezeichnung. | Bild: Moonshot AI
Die Testfragen des Benchmarks verlangen hochspezifische Antworten, wie die exakte Vogelart oder Produktbezeichnung. | Bild: Moonshot AIBesonders aufschlussreich ist die Unterscheidung zwischen häufigem und seltenem Wissen. Während bekannte Sehenswürdigkeiten oder populäre Markenlogos massenhaft im Internet vorkommen und entsprechend gut in Trainingsdaten vertreten sind, testen seltene Einträge das Wissen über obskure Objekte, Tier- und Pflanzenarten oder kulturelle Artefakte aus aller Welt.
Gemini und Kimi führen, aber unter 50 Prozent
Googles Gemini 3 Pro erreicht mit 47,4 Prozent die höchste Genauigkeit, dicht gefolgt von Kimi K2.5 mit 46,3 Prozent als bestem frei verfügbarem Modell. Claude Opus 4.5 von Anthropic kommt auf 36,8 Prozent, GPT-5.2 von OpenAI auf 28 Prozent. Selbst Googles älteres Gemini 2.5 Pro schneidet besser ab.
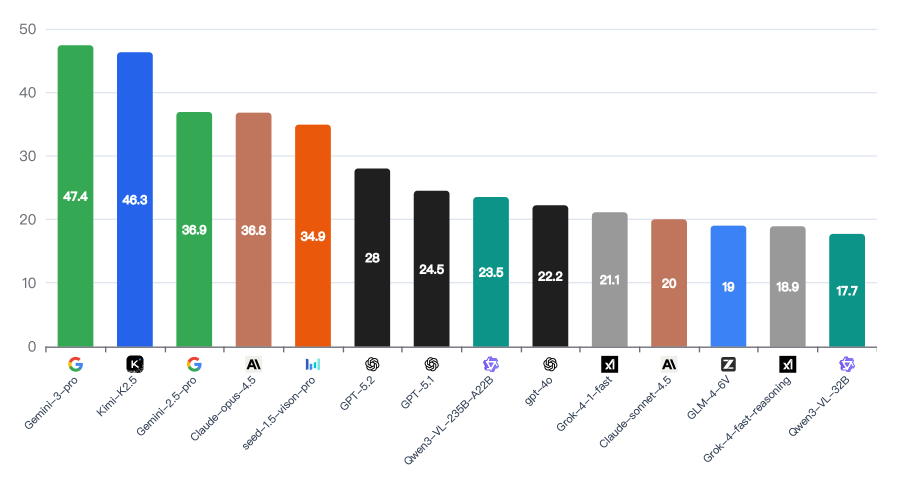 Selbst die leistungsfähigsten multimodalen Modelle wie Gemini 3 Pro und Kimi-K2.5 schaffen es nicht über die 50-Prozent-Marke bei der Objekterkennung hinaus. | Bild: Moonshot AI
Selbst die leistungsfähigsten multimodalen Modelle wie Gemini 3 Pro und Kimi-K2.5 schaffen es nicht über die 50-Prozent-Marke bei der Objekterkennung hinaus. | Bild: Moonshot AIDie Analyse nach Kategorien offenbart deutliche Wissenslücken. Bei Marken und Sport schneiden die Modelle vergleichsweise gut ab, vermutlich wegen der starken Präsenz dieser Themen in Web-Trainingsdaten. Bei Natur und Kultur hingegen fallen die Werte deutlich ab.
Hier neigen Modelle dazu, generische Oberbegriffe wie "Blume" statt spezifischer Artennamen zu verwenden. Die KI-Systeme sind also gewissermaßen popkulturell bewandert, während ihr Wissen über die natürliche Welt und kulturelles Erbe oberflächlich bleibt.
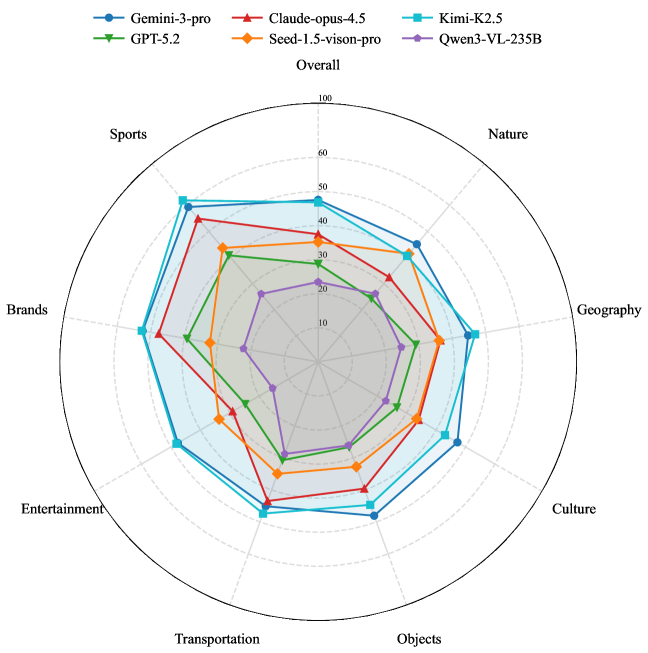 Im WorldVQA-Benchmark variiert die Leistung stark nach Themengebieten. Während populäre Kategorien wie Sport und Marken besser abschneiden, offenbaren Bereiche wie Natur und Kultur erhebliche Wissenslücken bei der Identifizierung spezifischer Entitäten. | Bild: Moonshot AI
Im WorldVQA-Benchmark variiert die Leistung stark nach Themengebieten. Während populäre Kategorien wie Sport und Marken besser abschneiden, offenbaren Bereiche wie Natur und Kultur erhebliche Wissenslücken bei der Identifizierung spezifischer Entitäten. | Bild: Moonshot AIModelle überschätzen sich systematisch
Ein weiterer Befund betrifft die Selbsteinschätzung der Modelle. Das Forschungsteam ließ die Systeme zusätzlich zur Antwort angeben, wie sicher sie sich auf einer Skala von 0 bis 100 sind.
Das Ergebnis ist eindeutig: Alle getesteten Modelle zeigen systematisches Übervertrauen. Gemini 3 Pro etwa gab in über 85 Prozent der Fälle eine Sicherheit von 95 Prozent oder höher an, unabhängig davon, ob die Antwort stimmt. Kimi K2.5 wies mit einem Kalibrierungsfehler von 37,9 Prozent die beste Selbsteinschätzung auf, lag aber ebenfalls noch weit vom Idealwert entfernt.
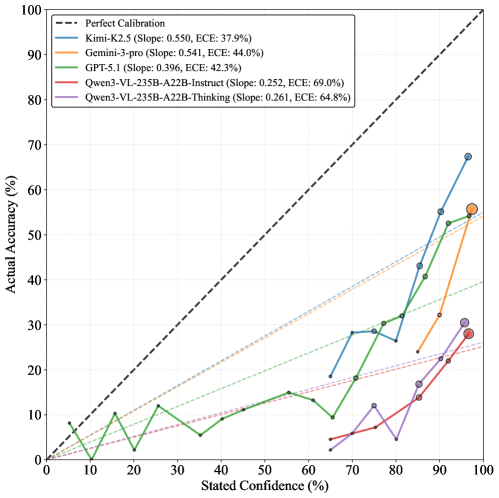 Trotz geringer tatsächlicher Genauigkeit geben viele Systeme eine extrem hohe Sicherheit an, was die Gefahr von Halluzinationen in der praktischen Anwendung verdeutlicht. | Bild: Moonshot AI
Trotz geringer tatsächlicher Genauigkeit geben viele Systeme eine extrem hohe Sicherheit an, was die Gefahr von Halluzinationen in der praktischen Anwendung verdeutlicht. | Bild: Moonshot AIDiese Diskrepanz zwischen Selbsteinschätzung und tatsächlicher Leistung deutet darauf hin, dass aktuelle Modelle keine zuverlässige interne Einschätzung ihrer eigenen Wissensgrenzen besitzen. Sie wissen nicht, was sie nicht wissen.
Schwierigkeit spiegelt echte Wissensknappheit wider
Um sicherzustellen, dass schwierige Fragen tatsächlich echten Wissensmangel widerspiegeln und nicht etwa auf mehrdeutige Bilder zurückgehen, validierten die Forscher ihre Einstufung anhand eines großen Referenzvokabulars. Die Analyse bestätigt den Zusammenhang: Je seltener eine Entität in realen Daten vorkommt, desto schwieriger ist sie für die Modelle zu erkennen.
Einfache Testfragen konzentrieren sich auf häufig vorkommende Objekte und Personen, während die als schwer eingestuften Fragen tatsächlich Wissen über Randerscheinungen abfragen. Die Schwierigkeit des Benchmarks stammt also aus genuiner Wissensknappheit, nicht aus Annotationsfehlern oder visueller Mehrdeutigkeit.
Was das für KI-Agenten bedeutet
Die Forscher sehen in WorldVQA einen notwendigen Schritt für die nächste Generation von KI-Assistenten. Wenn Modelle nicht zuverlässig erkennen können, was sie sehen, sind sie für Aufgaben in der realen Welt nur eingeschränkt einsetzbar.
Eine Einschränkung räumt das Team selbst ein: Der Benchmark misst Faktenwissen in einem stark isolierten Setting. Ob die Fähigkeit, spezifische Entitäten korrekt zu benennen, auch mit der Leistung bei komplexen praktischen Aufgaben zusammenhängt, bleibe eine offene Forschungsfrage. Der Datensatz und die Evaluationsskripte sind öffentlich zugänglich.
Aktuelle Studien decken wiederholt fundamentale Schwächen bei der Wissenszuverlässigkeit von KI-Modellen auf. Der AA-Omniscience-Benchmark von Artificial Analysis zeigte kürzlich, dass von 40 getesteten Modellen nur vier einen positiven Score erreichten. Auch dort war Gemini 3 Pro führend, zeigte aber gleichzeitig eine Halluzinationsrate von 88 Prozent.
Eine weitere Studie untersuchte, ob Sprachmodelle einschätzen können, wie schwer Prüfungsfragen für Menschen sind. Das Ergebnis: Die Modelle sind zu gut, um die Schwierigkeiten schwächerer Lernender nachzuempfinden. Die Forscher nannten das den "Fluch des Wissens". Auch dort zeigte sich, dass die Modelle ihre eigenen Grenzen nicht zuverlässig einschätzen können.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.


