Das chinesische KI-Unternehmen Alibaba hat mit Qwen-Image ein 20-Milliarden-Parameter-Modell entwickelt, das sich besonders durch präzise Textdarstellung in Bildern auszeichnet.
Das Modell beherrscht laut den Entwickler:innen viele verschiedene Stile. Nutzer:innen können Anime-Bilder mit mehreren Ladenschildern erstellen oder komplexe Powerpoint-Folien mit strukturierten Inhalten generieren. Das Modell beherrscht auch bilinguale Texte und kann nahtlos zwischen verschiedenen Sprachen wechseln.
 Qwen-Image kann Text in allen möglichen Stilen und Szenarien visualisieren. | Bild: Qwen
Qwen-Image kann Text in allen möglichen Stilen und Szenarien visualisieren. | Bild: Qwen Statt durch Funktionsaufrufe Präsentations-Software wie Powerpoint zu bedienen, schlägt Alibaba vor, solche Folien mit einem Bildmodell zu generieren. | Bild: Qwen
Statt durch Funktionsaufrufe Präsentations-Software wie Powerpoint zu bedienen, schlägt Alibaba vor, solche Folien mit einem Bildmodell zu generieren. | Bild: QwenÜber die reine Bildgenerierung hinaus unterstützt Qwen-Image auch Bildbearbeitung. Nutzer:innen können Stile ändern, Objekte hinzufügen oder entfernen und Posen von Personen anpassen. Zusätzlich kann das Modell klassische Computer-Vision-Aufgaben bewältigen, etwa Bildtiefen schätzen oder neue Blickwinkel auf Objekte erstellen.
 Qwen-Image kann teils subtile Veränderungen an einem Eingabebild vornehmen, ohne zu viel von dem Quellmaterial zu verändern. | Bild: Qwen
Qwen-Image kann teils subtile Veränderungen an einem Eingabebild vornehmen, ohne zu viel von dem Quellmaterial zu verändern. | Bild: QwenDie Architektur von Qwen-Image besteht laut technischem Bericht aus drei spezialisierten Komponenten: Das Text-Bild-Modell Qwen2.5-VL analysiert und versteht die Texteingaben, ein Variational AutoEncoder komprimiert Bilder in eine effizientere Darstellung, und ein Multimodal Diffusion Transformer generiert die finalen Bilder.
Anzeige
THE DECODER Newsletter
Die wichtigen KI-News direkt ins E-Mail-Postfach.
✓ 1x wöchentlich
✓ kostenlos
✓ jederzeit kündbar
Für die Positionierung von Textelementen im Bild entwickelten die Forscher eine neue Technik namens MSRoPE (Multimodal Scalable Rotary Position Embedding). Diese behandelt Text nicht mehr als lineare Kette, sondern ordnet Textteile räumlich entlang einer Bilddiagonale an. Dadurch kann das Modell besser verstehen, wo sich Text im Bild befinden soll und gleichzeitig mit verschiedenen Bildauflösungen arbeiten.
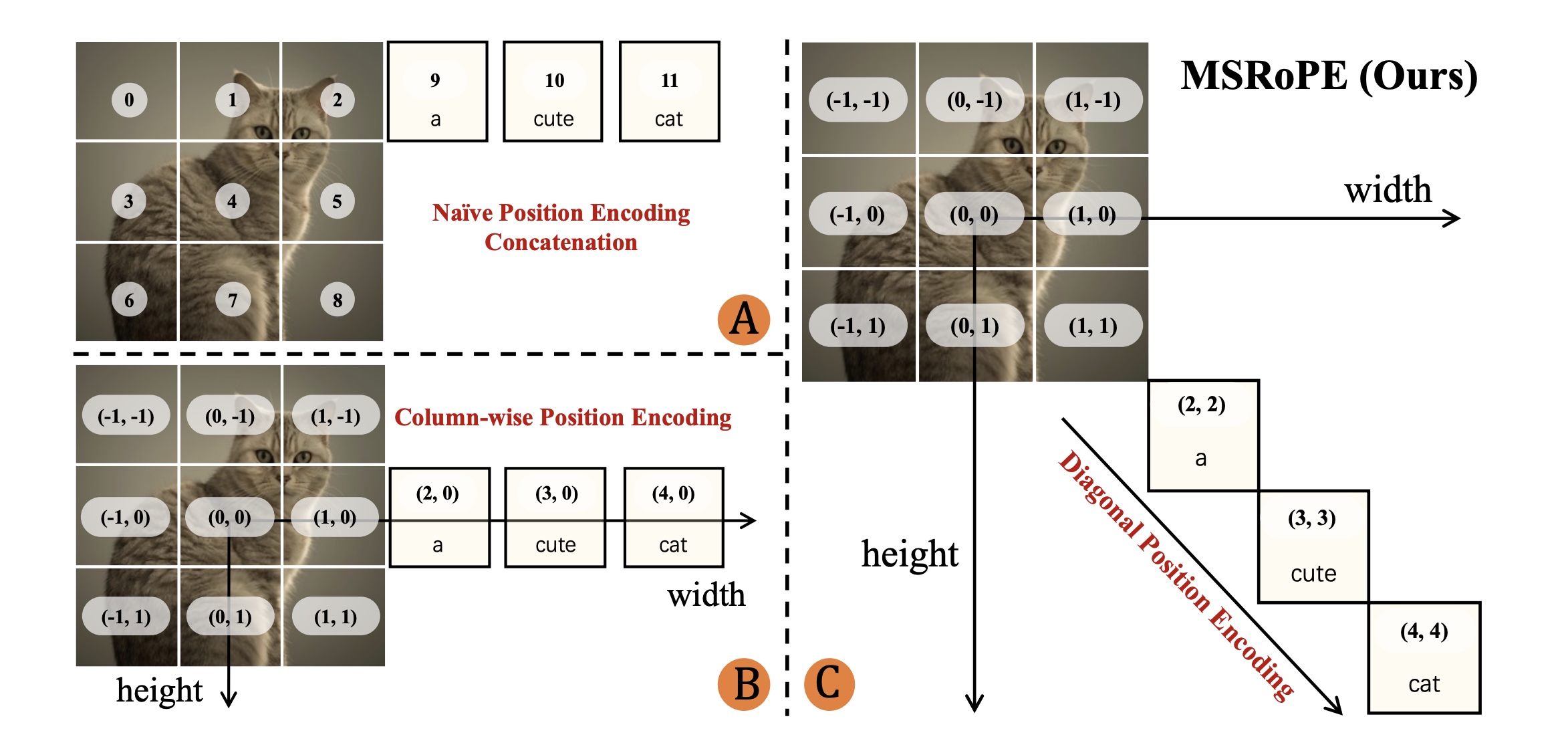 Während bisherige Positionierungsstrategien Text einfach am Raster anfügen, startet MSRoPE im Bildzentrum und ordnet Text entlang der Diagonale an, um Skalierbarkeit und Text-Bild-Ausrichtung bei höheren Auflösungen zu verbessern. | Bild: Qwen
Während bisherige Positionierungsstrategien Text einfach am Raster anfügen, startet MSRoPE im Bildzentrum und ordnet Text entlang der Diagonale an, um Skalierbarkeit und Text-Bild-Ausrichtung bei höheren Auflösungen zu verbessern. | Bild: QwenDatenbasis ohne KI-generierte Inhalte
Die Trainingsdaten umfassen laut Qwen-Team vier Kategorien: Naturbilder bilden mit 55 Prozent den Hauptanteil, gefolgt von Design-Inhalten wie Postern und Präsentationen (27 Prozent), Personenaufnahmen (13 Prozent) und synthetischen Daten (5 Prozent). Die Forscher verzichteten bewusst auf KI-generierte Bilder und setzten stattdessen auf kontrollierte Verfahren zur Texterstellung.
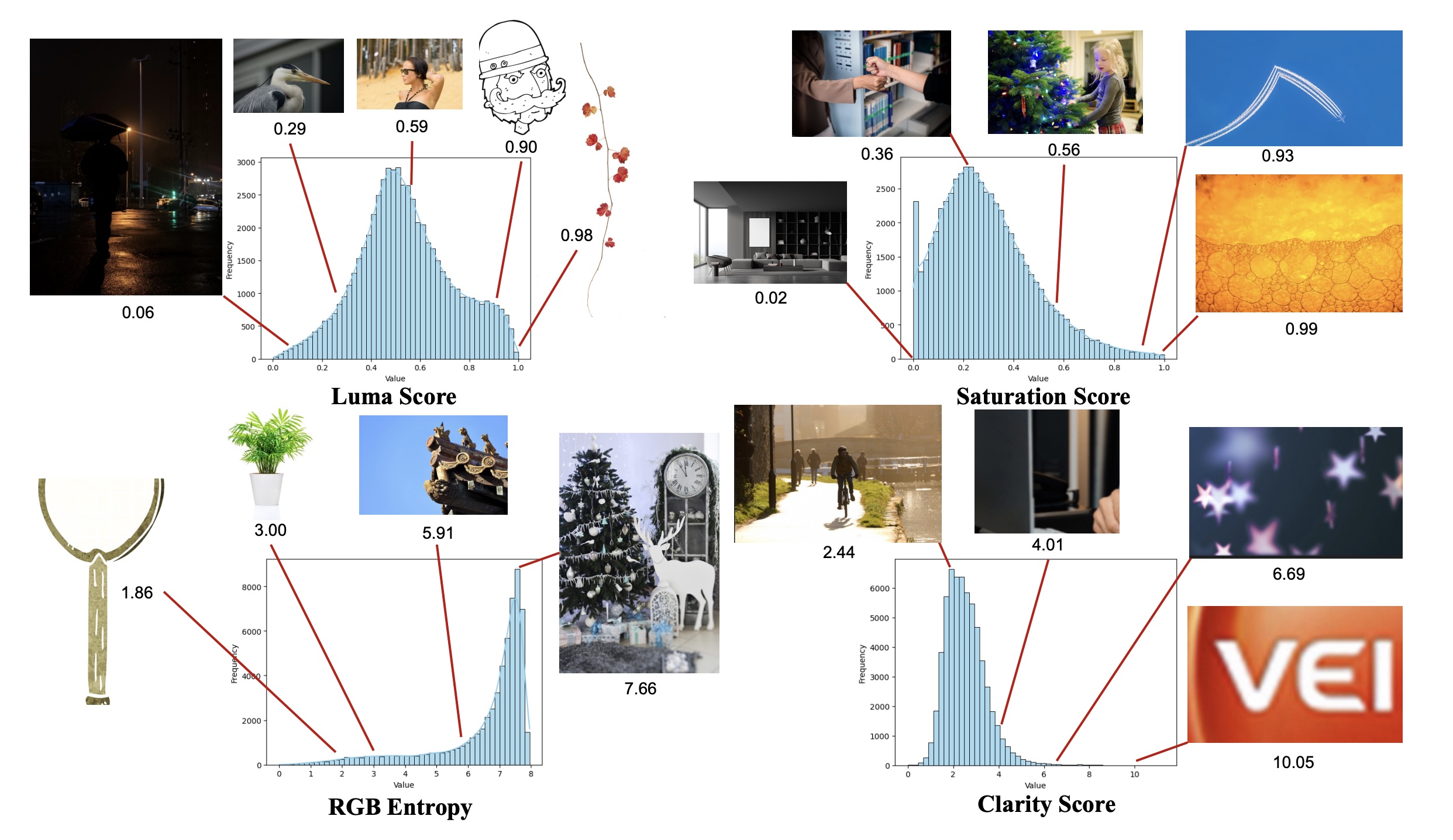 Extreme Werte deuten auf besonders helle, gesättigte, texturarme oder unscharfe Bilder hin und werden stärkerer Prüfung unterzogen. | Bild: Qwen
Extreme Werte deuten auf besonders helle, gesättigte, texturarme oder unscharfe Bilder hin und werden stärkerer Prüfung unterzogen. | Bild: QwenEin mehrstufiger Filterprozess sortiert minderwertige Inhalte aus. Drei verschiedene Strategien ergänzen die Datenbasis: Pure Rendering fügt Text auf einfache Hintergründe ein, Compositional Rendering integriert Text in realistische Szenen, und Complex Rendering erstellt strukturierte Vorlagen wie Powerpoint-Folien.
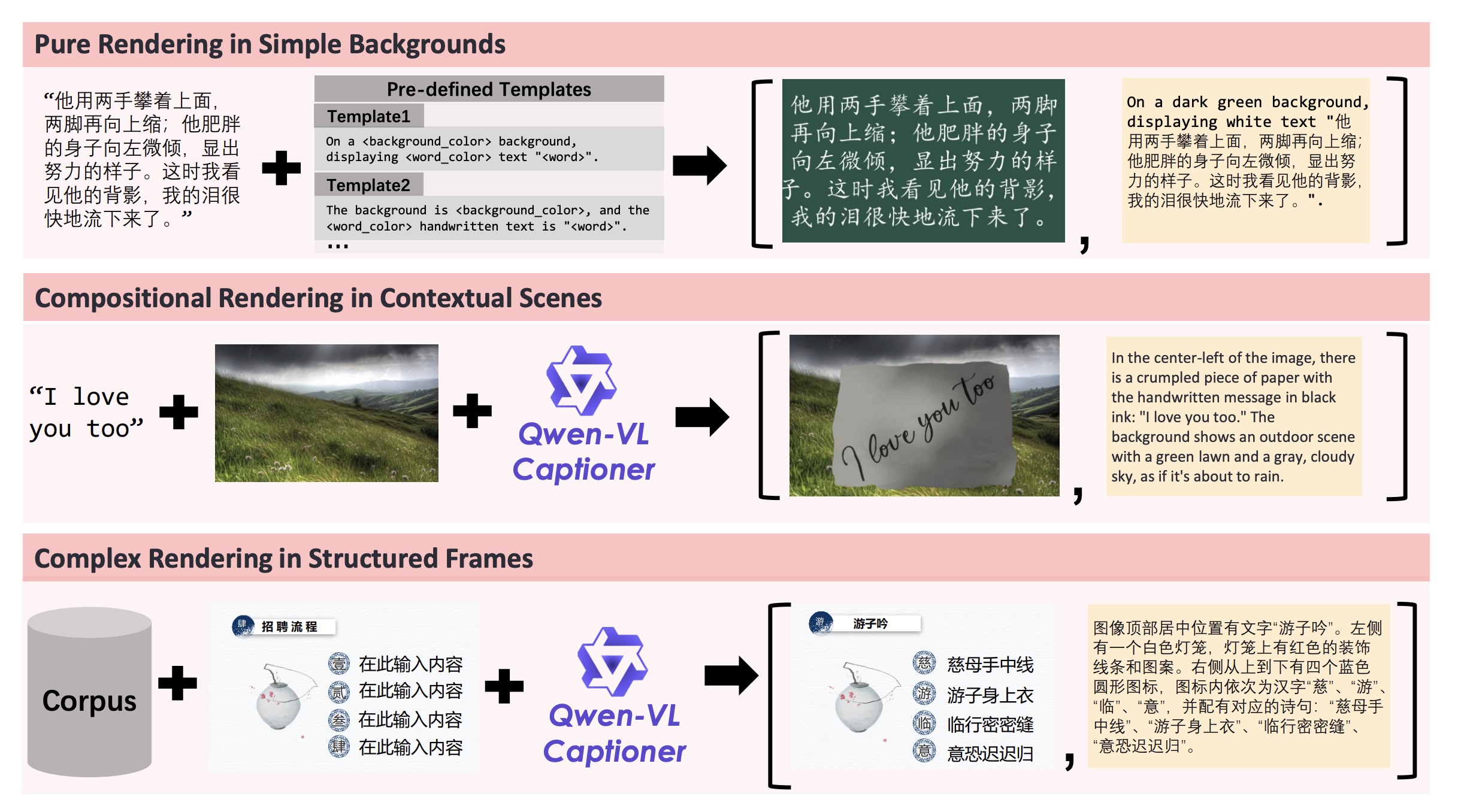 Die drei Rendering-Strategien erzeugen von reinem Text über handschriftliche Szenen bis hin zu komplexen Layouts diversifizierte Trainingsdaten für multimodale Modelle. | Bild: Qwen
Die drei Rendering-Strategien erzeugen von reinem Text über handschriftliche Szenen bis hin zu komplexen Layouts diversifizierte Trainingsdaten für multimodale Modelle. | Bild: QwenStarke Leistung auch verglichen mit kommerziellen Alternativen
Zur Bewertung entwickelte das Team eine Arena-Plattform, auf der Nutzer:innen anonym Bilder verschiedener Modelle bewerteten. Nach über 10.000 Vergleichen erreichte Qwen-Image Platz drei und lag damit vor kommerziellen Lösungen wie GPT-Image-1 und Flux.1 Kontext Pro.
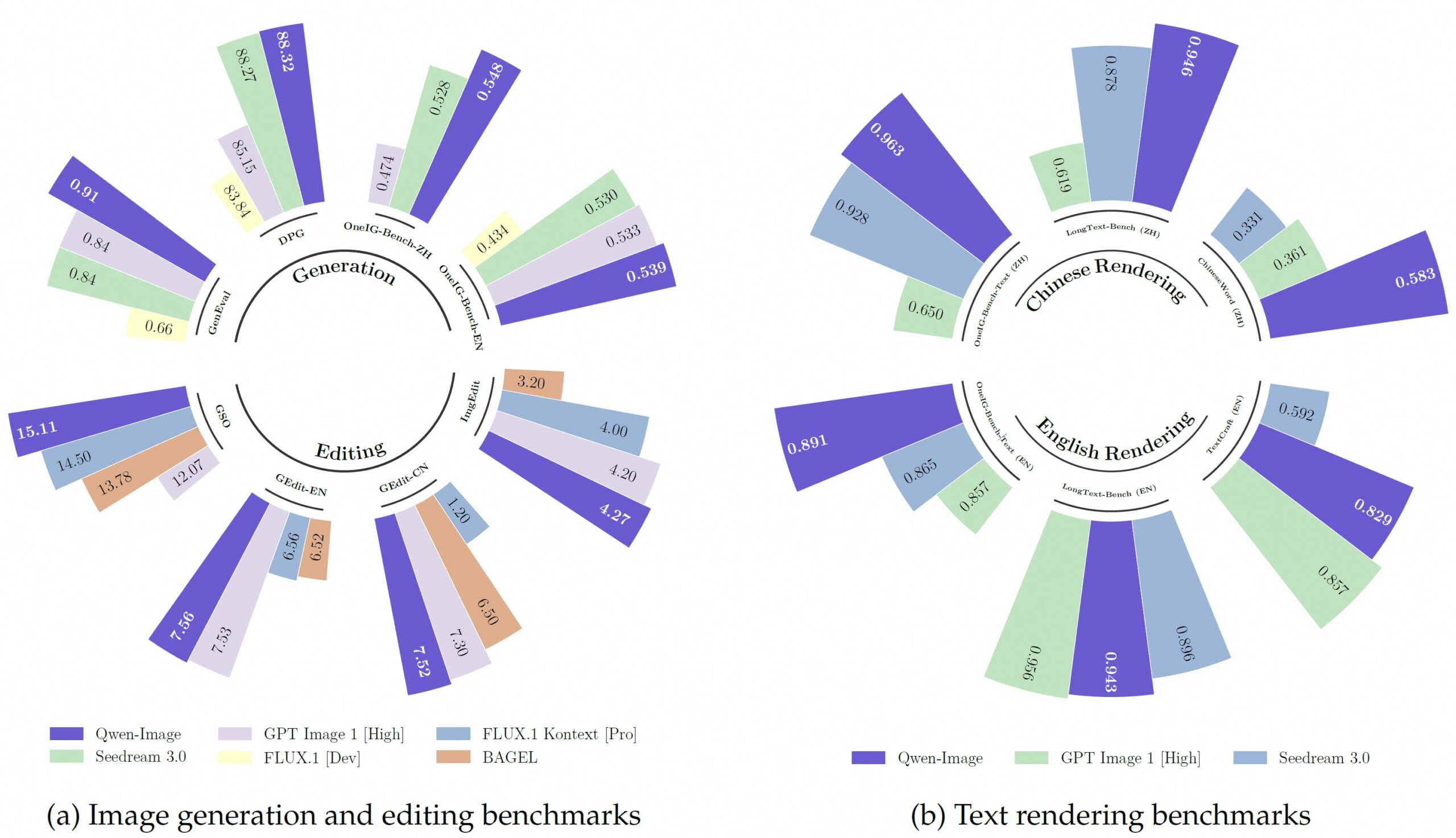 Im Vergleich zu Seedream 3.0, GPT-Image-1, Flux.1 und Bagel erzielt Qwen-Image in Bildgenerierung und -bearbeitung klare Höchstwerte. Gleichzeitig übertrifft das Modell bei chinesischem Textrendering alle Konkurrenten, liegt in englischer Sprache immerhin gleichauf. | Bild: Qwen
Im Vergleich zu Seedream 3.0, GPT-Image-1, Flux.1 und Bagel erzielt Qwen-Image in Bildgenerierung und -bearbeitung klare Höchstwerte. Gleichzeitig übertrifft das Modell bei chinesischem Textrendering alle Konkurrenten, liegt in englischer Sprache immerhin gleichauf. | Bild: QwenAuf verschiedenen Fachbenchmarks zeigt das Modell konsistent starke Leistungen. Beim GenEval-Test, der die Fähigkeit zur Objektgenerierung misst, erreichte Qwen-Image nach zusätzlichem Training einen Score von 0,91 und übertraf damit alle anderen Modelle. Bei chinesischen Schriftzeichen zeigt sich ein deutlicher Vorsprung gegenüber der Konkurrenz.
Empfehlung

Die Forscher sehen in Qwen-Image einen Schritt hin zu "Vision-Language User Interfaces", die Text und Bilder nahtlos kombinieren. Langfristig wollen sie Systeme entwickeln, die Bildverständnis und Bildgenerierung in einer einheitlichen Plattform vereinen. In dieser Richtung hatte Alibaba erst vor wenigen Wochen Qwen VLo vorgestellt, das bereits mit starken Textfähigkeiten beeindruckte.
Alibaba stellt das Modell kostenfrei auf Github und Hugging Face zur Verfügung, eine Demo gibt es ebenfalls.


