Ein internationales Forscherteam stellt den bislang größten Datensatz für Video-Reasoning vor, rund tausendmal umfangreicher als bisherige Alternativen. Die Ergebnisse offenbaren, dass selbst Sora 2 und Veo 3.1 bei Schlussfolgerungsaufgaben weit hinter Menschen zurückbleiben.
Ob ein Videomodell ein Puzzle lösen, eine physikalische Flugbahn vorhersagen oder Objekte nach Regeln sortieren kann, war bislang kaum systematisch untersucht. Es fehlte schlicht an ausreichend großen Datensätzen, und bisherige Benchmarks enthielten überwiegend nur Testdaten, aber kein Material zum Trainieren.
Ein über 50-köpfiges Konsortium von 32 Institutionen, darunter UC Berkeley, Stanford, Harvard und die University of Oxford, will diese Lücke nun schließen. Ihr Very Big Video Reasoning (VBVR) Suite umfasst über zwei Millionen Bilder und rund eine Million Videoclips, verteilt auf 200 kuratierte Aufgaben. Neun bestehende Benchmarks kommen zusammengerechnet auf etwa 12.800 Samples. Neben Testdaten stellt VBVR erstmals auch eine Million Trainingsbeispiele bereit.
Die Aufgaben folgen einer Taxonomie, die sich an Theorien menschlicher Kognition orientiert, von Aristoteles’ kognitiven Fähigkeiten bis zu Kants Kategorien des Verstandes. Die Forschenden unterscheiden fünf Kategorien: Abstraktion, Wissen, Wahrnehmung, Räumlichkeit und Transformation. Jede Kategorie wird als parametrisierter Aufgabengenerator umgesetzt, der Tausende verschiedener Instanzen erzeugen kann. Alle Aufgaben müssen unter anderem eine eindeutige Lösung haben und dürfen nicht aus einem einzelnen Standbild lösbar sein.
 Beispielaufgaben aus dem VBVR-Datensatz, von Formerkennung über Labyrinth-Navigation bis zur Physiksimulation. Jede Aufgabe verlangt mehrstufiges visuelles Schlussfolgern. | Bild: Wang et al.
Beispielaufgaben aus dem VBVR-Datensatz, von Formerkennung über Labyrinth-Navigation bis zur Physiksimulation. Jede Aufgabe verlangt mehrstufiges visuelles Schlussfolgern. | Bild: Wang et al.Sora 2 erreicht gut die Hälfte der menschlichen Leistung
Die Ergebnisse des zugehörigen Benchmarks VBVR-Bench fallen wenig schmeichelhaft aus. Menschen erzielen einen Gesamtwert von 0,974. OpenAIs Sora 2, das stärkste proprietäre Modell in der Studie, kommt auf 0,546. Google Deepminds Veo 3.1 folgt mit 0,480, Runway Gen-4 Turbo liegt bei 0,403 und Kuaishous Kling 2.6 bei 0,369. Die Open-Source-Modelle Wan2.2, CogVideoX, HunyuanVideo und LTX-2 rangieren zwischen 0,273 und 0,371.
VBVR-Bench verzichtet bewusst darauf, ein Sprachmodell als Richter einzusetzen. Da die meisten Aufgaben eine eindeutige Lösung haben, messen regelbasierte Bewertungen räumliche Präzision, Pfadkorrektheit und logische Validität direkt. Dass diese automatischen Scores die tatsächliche Qualität zuverlässig abbilden, bestätigen die Forschenden mit einem Abgleich gegen menschliche Urteile, der eine sehr hohe statistische Übereinstimmung ergibt.
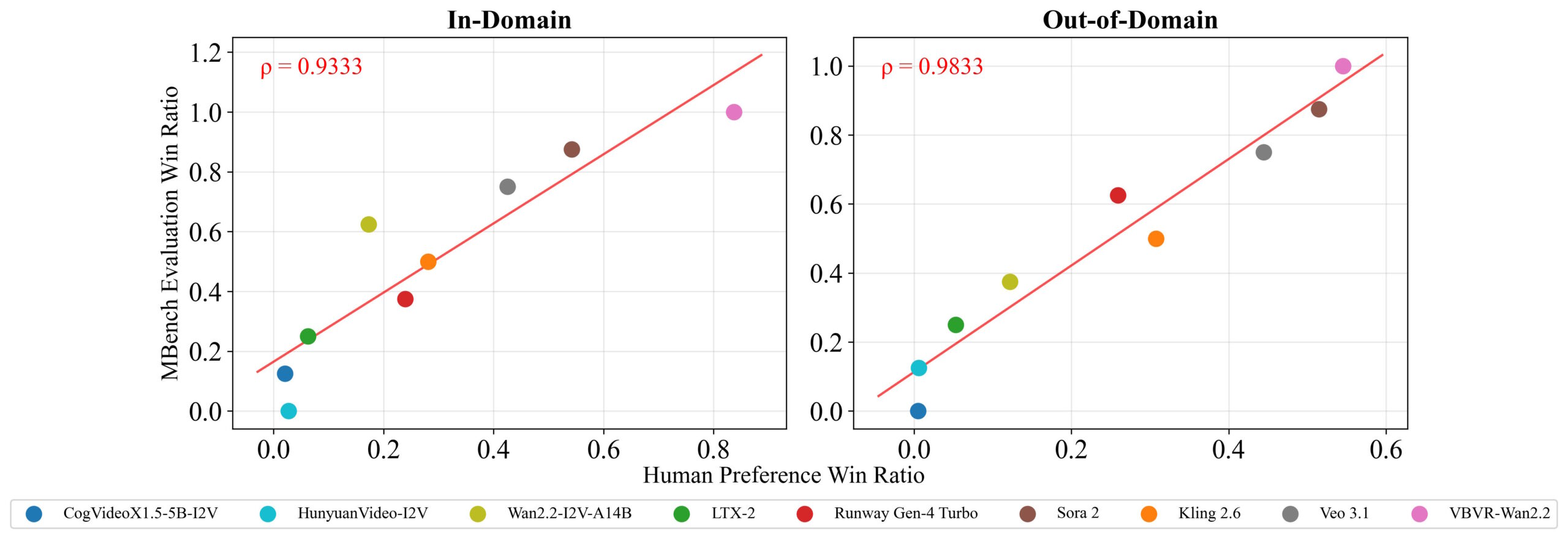 Abgleich zwischen automatischer Bewertung und menschlichen Urteilen für In-Domain- und Out-of-Domain-Aufgaben. Die hohe Übereinstimmung bestätigt die Zuverlässigkeit der regelbasierten Evaluation. | Bild: Wang et al.
Abgleich zwischen automatischer Bewertung und menschlichen Urteilen für In-Domain- und Out-of-Domain-Aufgaben. Die hohe Übereinstimmung bestätigt die Zuverlässigkeit der regelbasierten Evaluation. | Bild: Wang et al.Feinabgestimmtes Open-Source-Modell schlägt alle proprietären Systeme
Das vielversprechendste Ergebnis liefert VBVR-Wan2.2, eine feinabgestimmte Variante von Wan2.2. Der Gesamtwert steigt auf 0,685, eine Verbesserung von 84,6 Prozent gegenüber dem Basismodell, und übertrifft damit sämtliche getesteten proprietären Systeme.
Die Skalierungsstudie zeigt allerdings eine klare Sättigungsgrenze. Die Leistung auf bekannten Aufgabentypen steigt bis etwa 400.000 Trainingsbeispiele auf 0,771 und stagniert dann. Auf gänzlich unbekannten Aufgabentypen verbessert sie sich auf 0,610, bleibt aber um 15 Prozentpunkte zurück. Die Forschenden sehen darin fundamentale Engpässe heutiger Videogenerierungsarchitekturen. Mehr Daten allein lösten das Problem nicht.
 Qualitative Vergleiche zwischen VBVR-Wan2.2 und Sora 2 an identischen Aufgaben. VBVR-Wan2.2 setzt Anweisungen präziser um, zeigt aber bei längeren Sequenzen noch Schwächen. | Bild: Wang et al.
Qualitative Vergleiche zwischen VBVR-Wan2.2 und Sora 2 an identischen Aufgaben. VBVR-Wan2.2 setzt Anweisungen präziser um, zeigt aber bei längeren Sequenzen noch Schwächen. | Bild: Wang et al.Kontrollierbarkeit als Voraussetzung für logisches Schlussfolgern
Eine qualitative Analyse vergleicht VBVR-Wan2.2 direkt mit Sora 2. Die Forschenden formulieren dabei eine zentrale Erkenntnis: Wenn ein Modell die Szene während der Generierung frei umschreibt, also Hintergrund, Layout oder Objektidentität verändert, werden Zwischenzustände unzuverlässig und jede darauf aufbauende Schlussfolgerung nicht mehr überprüfbar.
Bei einer Löschaufgabe etwa führt Sora 2 nach dem Entfernen des Zielobjekts unnötige Umordnungen aus, während VBVR-Wan2.2 präzise nur das Angewiesene umsetzt. Bei einer Rotationsaufgabe scheitert Sora 2 daran, Zielregion und zu manipulierendes Objekt zu unterscheiden. VBVR-Wan2.2 zeigt sogar emergente Fähigkeiten jenseits der Trainingsaufgaben, etwa konsistente Vervollständigungsstrategien bei Symmetrieaufgaben. Bei längeren Sequenzen kann es jedoch zu Flackern oder Duplikation kommen.
Kognitive Fähigkeiten entwickeln sich nicht gleichmäßig
Eine Korrelationsanalyse über alle Modelle hinweg zeigt bemerkenswerte Muster. Modelle, die gut bei Wissensaufgaben abschneiden, sind tendenziell auch bei räumlichen Aufgaben stark, was neurowissenschaftliche Befunde zur Doppelrolle des Hippocampus bei Navigation und konzeptuellem Lernen spiegelt.
Umgekehrt geht gutes Abschneiden bei Wissensaufgaben mit Schwächen in der Wahrnehmung einher. Abstraktion korreliert mit keiner anderen Fähigkeit positiv – stattdessen geht eine Stärke bei Abstraktionsaufgaben sogar mit Schwächen bei Transformations- und Räumlichkeitsaufgaben einher.
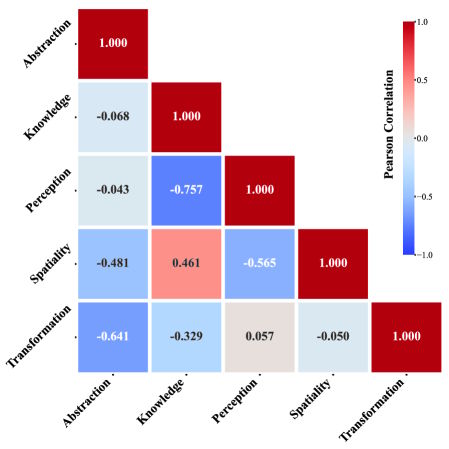 Korrelationsmatrix der fünf kognitiven Fähigkeiten über alle getesteten Modelle. Wissen und Räumlichkeit korrelieren positiv, Wissen und Wahrnehmung stark negativ. | Bild: Wang et al.
Korrelationsmatrix der fünf kognitiven Fähigkeiten über alle getesteten Modelle. Wissen und Räumlichkeit korrelieren positiv, Wissen und Wahrnehmung stark negativ. | Bild: Wang et al.Daten, Benchmark-Toolkit und Modelle sind auf video-reason.com öffentlich verfügbar. Die Forschenden betonen, dass architektonische Fortschritte wie State-Tracking oder Selbstkorrekturmechanismen nötig seien, um die beobachteten Leistungsgrenzen zu überwinden.
Bereits im September 2025 hatte eine Studie unter Beteiligung von Google DeepMind nahegelegt, dass Googles Videomodell Veo 3 überraschend vielseitige Zero-Shot-Fähigkeiten besitzt, also ohne aufgabenspezifisches Training Labyrinthe lösen, Symmetrien erkennen oder physikalische Zusammenhänge simulieren kann. Die Forscher sahen darin ein frühes Anzeichen dafür, dass Videomodelle zu universellen Grundlagen für maschinelles Sehen werden könnten, ähnlich wie es große Sprachmodelle für die Textverarbeitung bereits sind. Manche, wie Deepmind-CEO Demis Hassabis glauben, dass Videomodelle eine Grundlage für Weltmodelle sein könnten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.

