![]()
Online-Journalist Matthias ist Gründer und Herausgeber von THE DECODER. Er ist davon überzeugt, dass Künstliche Intelligenz die Beziehung zwischen Mensch und Computer grundlegend verändern wird.
Sogenannte "Reasoning-Modelle" generieren deutlich mehr Wörter (Token), bevor sie antworten. Offene KI-Modelle benötigen dabei mitunter drei- bis viermal mehr Token als geschlossene Modelle wie Grok-4 oder OpenAI, zeigt eine Analyse von Nous Research. Besonders bei einfachen Wissensfragen produzieren offene Modelle unnötige Gedankenschritte, was trotz niedrigerer Tokenpreise zu höheren Gesamtkosten führen kann.
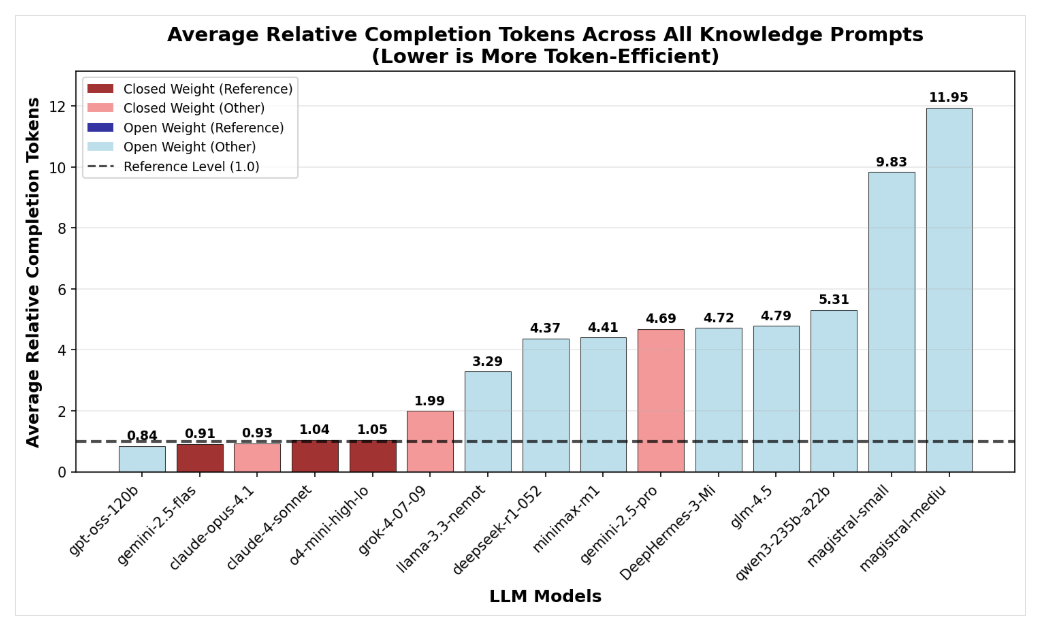 Anzahl der durchschnittlich verbrauchten Token zur Lösung einer Aufgabe. | Bild: Nous Research
Anzahl der durchschnittlich verbrauchten Token zur Lösung einer Aufgabe. | Bild: Nous ResearchOpenAIs gpt-oss-120b zeige jedoch, dass auch Open-Source-Modelle mit sehr kurzen Denkpfaden effizient arbeiten können, insbesondere bei Mathematikaufgaben. Mistrals Magistral-Modelle hingegen fallen durch hohen Tokenverbrauch auf. Die Token-Effizienz hängt stark vom Aufgabentyp ab.
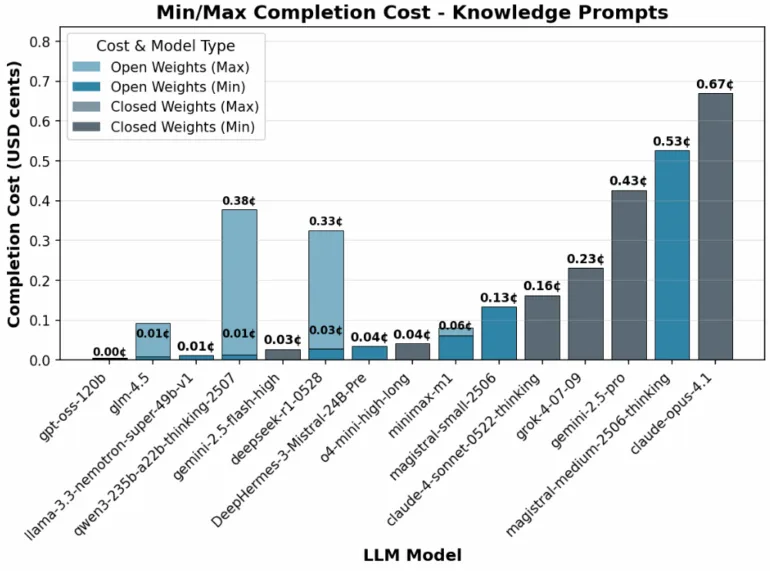 Obwohl die Basispreise geringer sind, können Open-Source-Reasoning-Modelle teurer sein, wenn sie mehr Token verbrauchen. | Bild: Nous Research
Obwohl die Basispreise geringer sind, können Open-Source-Reasoning-Modelle teurer sein, wenn sie mehr Token verbrauchen. | Bild: Nous ResearchUnterstütze unsere unabhängige, frei zugängliche Berichterstattung. Jeder Betrag hilft und sichert unsere Zukunft. Jetzt unterstützen:
![]()
Online-Journalist Matthias ist Gründer und Herausgeber von THE DECODER. Er ist davon überzeugt, dass Künstliche Intelligenz die Beziehung zwischen Mensch und Computer grundlegend verändern wird.


