Helios soll als erstes 14B-Videomodell 19,5 FPS auf einer einzelnen GPU erreichen und minutenlange Videos erzeugen. Code und Modell sind offen verfügbar.
Während bisherige Modelle meist nur 5–10 Sekunden lange Clips erzeugen und dafür teils Minuten benötigen, setzen Echtzeitansätze für längere Videos auf deutlich kleinere 1,3B-Modelle mit Qualitätsproblemen. Größere Ansätze wie Krea-RealTime-14B schaffen auf einer H100 lediglich 6,7 FPS und leiden unter starkem Drifting.
Helios basiert auf Wan-2.1-14B, das für fünf Sekunden Video rund 50 Minuten auf einer A100 braucht. Das Training erfolgt in drei Stufen: Helios-Base (Architektur und Anti-Drifting), Helios-Mid (Token-Kompression, 1,05 FPS) und Helios-Distilled, das durch Reduktion auf drei Rechenschritte die maximale Geschwindigkeit erreicht.
In Entwickler-Benchmarks erreicht die destillierte Helios-Version 19,53 FPS und ist damit schneller als einige kleinere destillierte Modelle. SANA Video Long mit 2 Milliarden Parametern – rund siebenmal kleiner – erzielt lediglich 13,24 FPS.
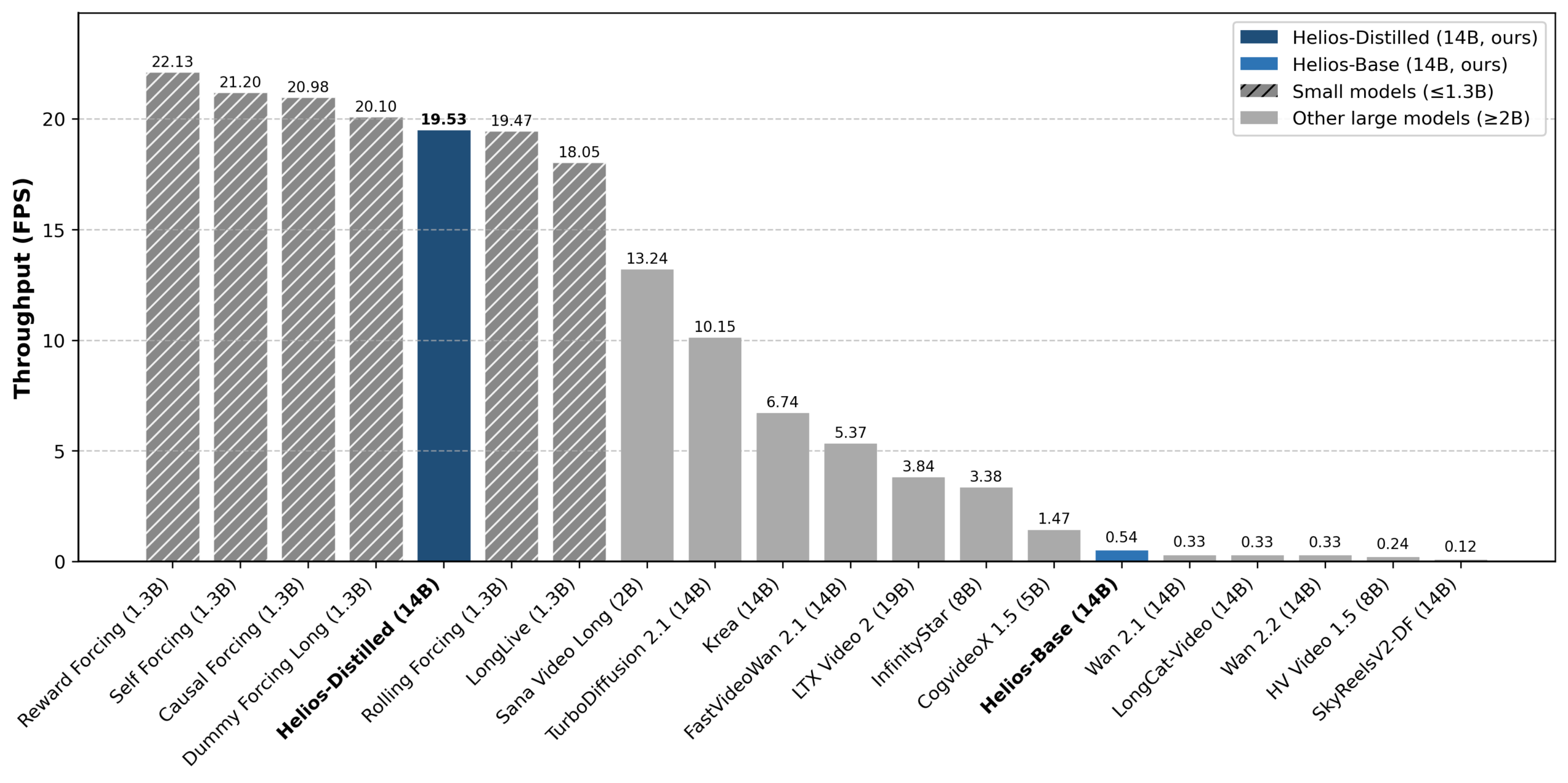 Helios-Distilled erreicht mit 19,53 FPS eine Geschwindigkeit auf dem Niveau deutlich kleinerer 1,3B-Modelle, während andere Modelle gleicher Größe teils unter 1 FPS liegen. | Bild: Yuan et al.
Helios-Distilled erreicht mit 19,53 FPS eine Geschwindigkeit auf dem Niveau deutlich kleinerer 1,3B-Modelle, während andere Modelle gleicher Größe teils unter 1 FPS liegen. | Bild: Yuan et al.Bei der Videoqualität erzielt Helios für Kurzvideos mit 81 Frames einen Gesamtscore von 6,00 und übertrifft damit laut Autoren alle destillierten Modelle; das Niveau sei mit den meisten Basismodellen dieser Größe vergleichbar. Bei Langvideos erreicht Helios 6,94 Punkte und liegt damit knapp vor dem bisherigen Spitzenreiter Reward Forcing (6,88). Eine Nutzerstudie mit 200 Teilnehmenden bestätigt die Ergebnisse.
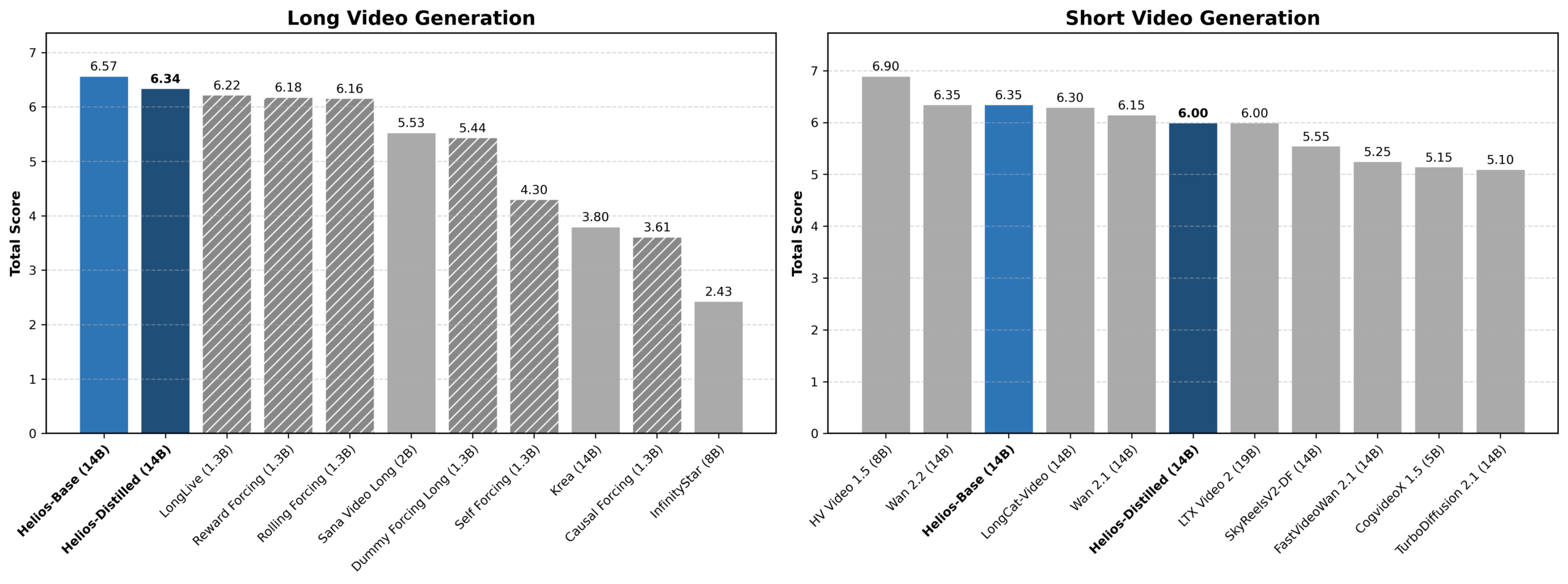 Bei der Videoqualität führt Helios-Base die Langvideo-Wertung an und liegt bei Kurzvideos auf dem Niveau deutlich größerer Basismodelle. | Bild: Yuan et al.
Bei der Videoqualität führt Helios-Base die Langvideo-Wertung an und liegt bei Kurzvideos auf dem Niveau deutlich größerer Basismodelle. | Bild: Yuan et al.Einfache Trainingsstrategien gegen das Drifting-Problem
Länger generierte Videos verlieren typischerweise an Qualität, Farbkonsistenz und inhaltlicher Kohärenz. Bisherige Modelle setzen dagegen aufwendige Techniken ein, etwa sogenanntes Self-Forcing, bei dem das Modell während des Trainings seine eigenen Ausgaben als Eingabe verwendet, um den Unterschied zwischen Training und Anwendung zu verringern. Helios verzichtet auf solche Verfahren.
 Die drei typischen Driftingmuster bei langer Videogenerierung: Positionsverschiebung, Farbverschiebung und Restaurierungsartefakte, die sich als Rauschen oder Unschärfe äußern können. | Bild: Yuan et al.
Die drei typischen Driftingmuster bei langer Videogenerierung: Positionsverschiebung, Farbverschiebung und Restaurierungsartefakte, die sich als Rauschen oder Unschärfe äußern können. | Bild: Yuan et al.Stattdessen identifizieren die Autoren drei typische Driftingmuster und schlagen einfachere Gegenmaßnahmen vor. Eine relative Positionskodierung verhindert, dass das Modell bei langen Videos auf unbekannte Positionsindizes stößt und dadurch repetitive Bewegungen erzeugt. Ein sogenannter First-Frame Anchor behält das erste Bild stets im Gedächtnis des Modells und dient als visueller Stabilitätsanker gegen Farbverschiebungen. Eine gezielte Störungssimulation während des Trainings macht das Modell robuster gegenüber seinen eigenen Fehlern, die sich sonst über die Zeit aufschaukeln.
Ein Modell für Text, Bild und Video als Eingabe
Helios verwendet eine einheitliche Architektur, die Text-zu-Video, Bild-zu-Video und Video-zu-Video in einem einzigen Framework unterstützt. Der Wechsel zwischen diesen Aufgaben erfolgt automatisch über die Darstellung des bisherigen Kontexts.
Ist dieser leer, generiert das Modell aus Text. Ist nur der letzte Frame im Kontext vorhanden, arbeitet es als Bildanimation. Enthält er mehrere Frames, setzt es ein bestehendes Video fort. Darüber hinaus können Nutzer den Textprompt während der Videoerzeugung ändern, wobei eine schrittweise Überblendung zwischen altem und neuem Prompt abrupte visuelle Brüche vermeiden soll.
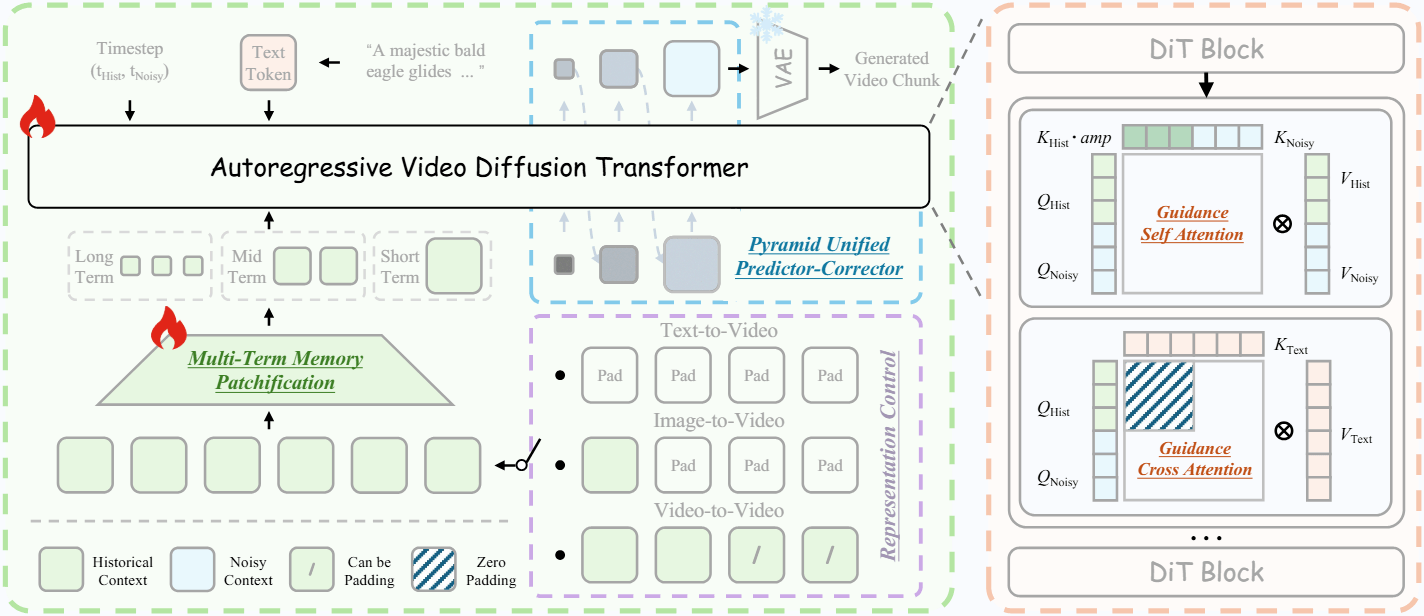 Die Architektur von Helios komprimiert den historischen Kontext über drei Zeitskalen und wechselt automatisch zwischen Text-, Bild- und Video-Eingabe. | Bild: Yuan et al.
Die Architektur von Helios komprimiert den historischen Kontext über drei Zeitskalen und wechselt automatisch zwischen Text-, Bild- und Video-Eingabe. | Bild: Yuan et al.Das Modell wurde in einem dreistufigen Verfahren mit 0,8 Millionen kurzen Videoclips (unter zehn Sekunden) trainiert. Die Auflösung ist derzeit auf 384 × 640 Pixel begrenzt, zudem treten an Segmentübergängen weiterhin Flickerartefakte auf. Mangels offenem Benchmark für Echtzeit-Langvideos entwickelten die Forscher mit HeliosBench einen eigenen Testdatensatz mit 240 Prompts.
Aggressive Kompression drückt Rechenkosten auf Bruchteil
Helios erreicht seine Geschwindigkeit ohne gängige Beschleunigungstechniken wie KV-Cache, sparsame Aufmerksamkeitsmechanismen oder Quantisierung. Stattdessen komprimiert das Modell die Eingabedaten massiv auf zwei Ebenen.
Eine hierarchische Gedächtnisstruktur teilt den bisherigen Videoverlauf in drei Zeitskalen auf. Zeitlich nahe Frames werden wenig komprimiert, weit zurückliegende stark. Das reduziert die Anzahl der zu verarbeitenden Tokens um den Faktor acht.
Ein mehrstufiges Sampling-Verfahren verringert die Tokens des zu erzeugenden Videoteils um den Faktor 2,29, indem frühe Schritte in niedrigerer Auflösung stattfinden und erst spätere Schritte feine Details hinzufügen. Zusammen sollen diese Maßnahmen die Rechenkosten auf ein Niveau drücken, das mit der Erzeugung einzelner Bilder vergleichbar ist.
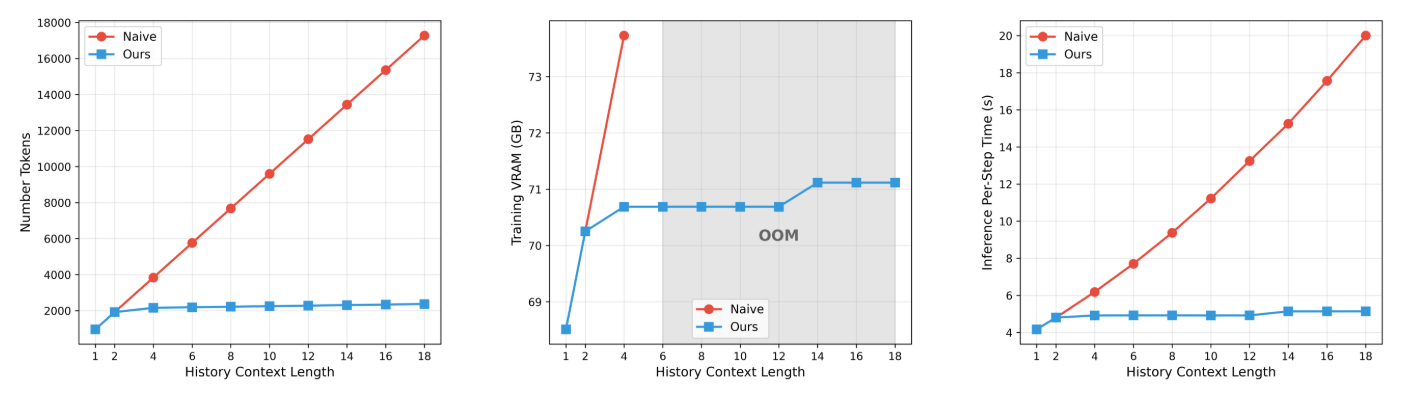 Mit zunehmender Kontextlänge steigen Token-Anzahl, Speicherbedarf und Inferenzzeit beim naiven Ansatz linear an, während Helios nahezu konstant bleibt. Ab einer Kontextlänge von 6 läuft dem herkömmlichen Ansatz der Speicher über. | Bild: Yuan et al.
Mit zunehmender Kontextlänge steigen Token-Anzahl, Speicherbedarf und Inferenzzeit beim naiven Ansatz linear an, während Helios nahezu konstant bleibt. Ab einer Kontextlänge von 6 läuft dem herkömmlichen Ansatz der Speicher über. | Bild: Yuan et al.Zusätzlich reduziert eine spezielle Destillationstechnik die Anzahl der nötigen Berechnungsschritte pro Videosegment von 50 auf 3. Anders als bisherige Ansätze verwendet Helios dabei ausschließlich echte Videodaten als Kontext und generiert nur ein einziges Segment pro Trainingsschritt. Ein zusätzliches gegnerisches Trainingsziel, ähnlich einem GAN, soll die Qualität über die Grenzen des Lehrermodells hinaus verbessern.
Durch die Token-Kompression lässt sich Helios in den ersten beiden Trainingsstufen ohne verteiltes Rechnen auf einer einzelnen GPU trainieren. In der dritten Trainingsstufe, die vier vollständige Modelle gleichzeitig erfordert, passen diese dank verschiedener Speicheroptimierungen in 80 GB GPU-Speicher. Eigens entwickelte Berechnungskerne für häufig verwendete Operationen beschleunigen Training und Anwendung laut den Forschern um rund 14 Prozent gegenüber der Standard-Implementierung.
Helios ist als Open-Weight-Modell auf Github und Hugging Face verfügbar, bei letzterem steht auch eine Demo bereit. Auf der Projektseite gibt es zahlreiche der generierten Videobeispiele zu sehen. Das Projekt sei rein für Forschungszwecke und solle nicht in Bytedance-Produkte integriert werden.
Vor kurzem hatte Bytedance bereits mit Seedance 2.0 für Aufsehen gesorgt, einem multimodalen Videogenerierungsmodell, das Bilder, Videos, Audio und Text gleichzeitig verarbeiten kann. Seedance benötigt zur Generierung deutlich mehr Ressourcen und produziert höchstens 15-Sekunden-Clips, jedoch in weit höherer Bildqualität.

