Cohere bringt mit Command A Vision ein KI-Modell heraus, das besonders gut Bilder, Diagramme, PDFs und andere visuelle Daten analysieren kann. Laut Cohere schneidet das Modell in Benchmarks etwas besser ab als GPT-4.1, Llama 4 Maverick und Mistral Medium 3.
Die OCR-Funktion versteht nicht nur Text, sondern auch das Layout und die Struktur von Dokumenten wie Rechnungen oder Formularen und kann die extrahierten Daten strukturiert im JSON-Format ausgeben. Zudem kann Command A Vision reale Szenen analysieren, um etwa Risiken in Industrieanlagen zu erkennen.
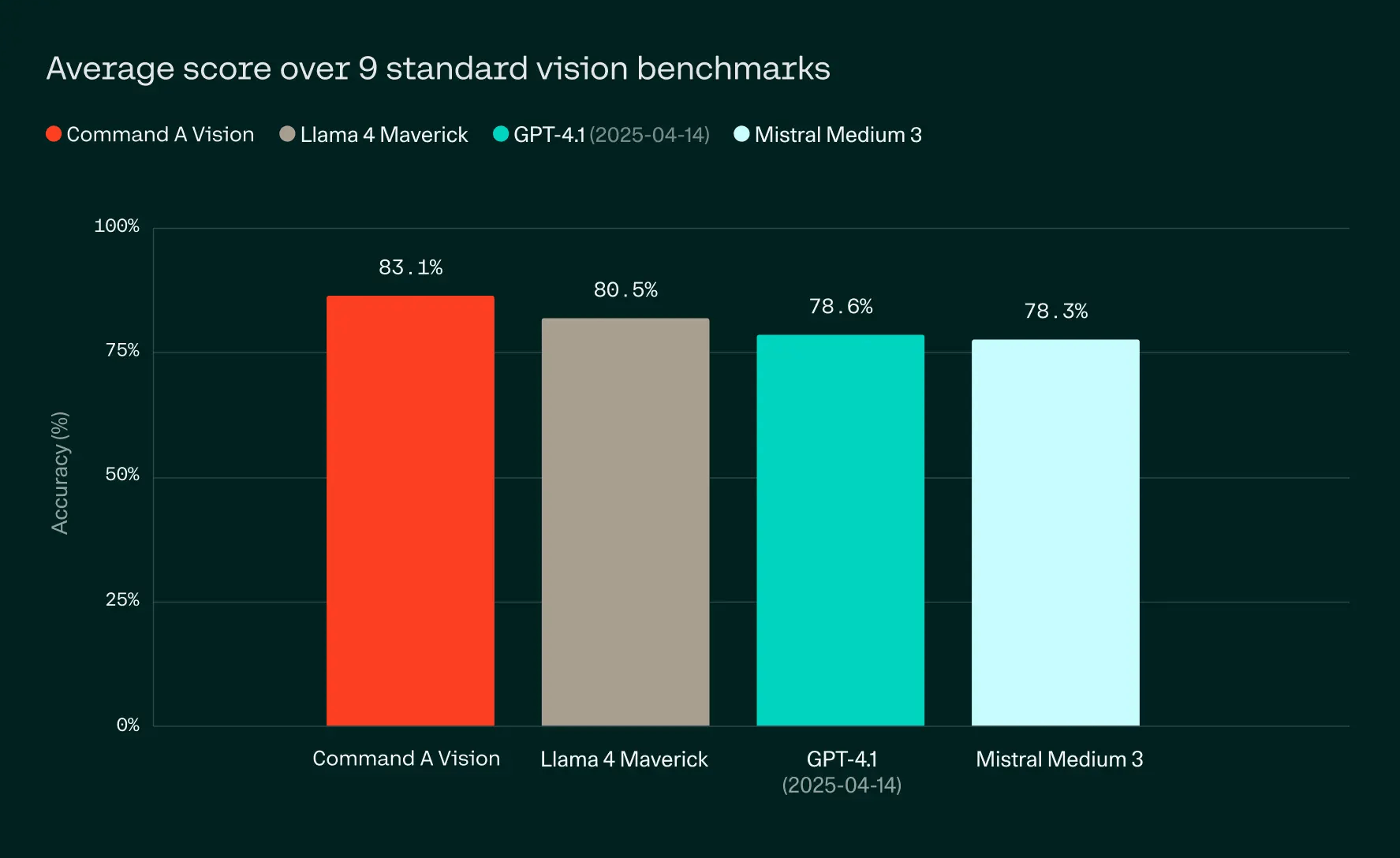 Bild: Cohere
Bild: CohereCommand A Vision ist über die Cohere-Plattform und für Forschungszwecke über Hugging Face verfügbar. Das Modell läuft lokal mit zwei A100-Grafikprozessoren oder einem H100-Prozessor mit 4-Bit-Quantisierung.


