Wenn große Sprachmodelle halluzinieren, hinterlassen sie messbare Spuren in ihren eigenen Berechnungen. Forscher der Sapienza Universität Rom haben eine trainingsfreie Methode entwickelt, die diese Spuren nutzt und dabei besser generalisiert als bisherige Verfahren.
Ob ein LLM bei einer konkreten Antwort halluziniert, lässt sich bislang nur schwer automatisch feststellen. Denn streng genommen halluzinieren große Sprachmodelle immer: Sie generieren Text stets auf Basis statistischer Wahrscheinlichkeiten, nicht auf Basis von Wissen oder Fakten. Jede Ausgabe ist eine Art kontrollierte Halluzination – nur fällt sie meist nicht als Fehler auf, weil das Ergebnis zufällig mit der Realität übereinstimmt.
Zum Problem wird die Halluzination erst, wenn das Modell dabei faktisch falsche, erfundene oder widersprüchliche Inhalte produziert. Ein Forschungsteam der Sapienza Universität Rom schlägt in einem auf der ICLR 2026 veröffentlichten Paper einen ungewöhnlichen Weg ein, um genau diese fehlerhaften Halluzinationen zu erkennen: Die Forscher betrachten die letzte Berechnungsschicht eines LLMs, die sogenannte Softmax-Schicht, aus einer neuen Perspektive.
Diese Schicht wandelt die Rohwerte des Modells in Wahrscheinlichkeiten für das nächste Wort um. Das Team interpretiert sie als sogenanntes Energy-Based Model, ein physiknahes Wahrscheinlichkeitsmodell, in dem niedrige Energiewerte hohe Wahrscheinlichkeiten bedeuten.
Autoregressive Sprachmodelle sagen ein Wort nach dem anderen voraus. Bei jedem Schritt berechnet das Modell, wie wahrscheinlich jedes mögliche nächste Wort ist. Mathematisch sollten dabei bestimmte Energiewerte zwischen aufeinanderfolgenden Vorhersageschritten identisch sein, weil sie dieselbe Größe aus zwei verschiedenen Blickwinkeln beschreiben.
In der Praxis weichen sie jedoch voneinander ab, schreiben die Forscher. Diese Differenz bezeichnen sie als "Spilled Energy", also verschüttete Energie. Sie korreliert laut dem Paper stark mit Fehlern: Halluziniert ein LLM, fällt die verschüttete Energie deutlich höher aus als bei korrekten Antworten.
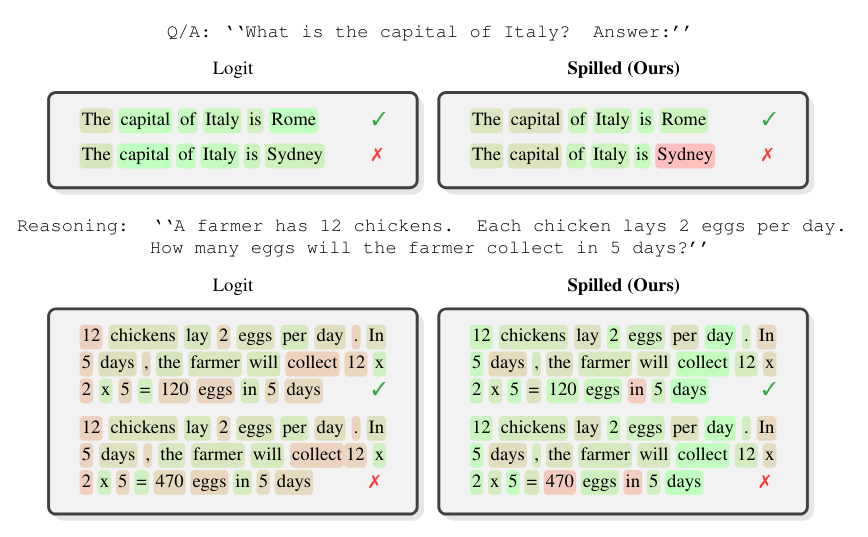 Spilled Energy erkennt die fehlerhaften Antwort-Token "Sydney" und "470" zuverlässiger als die herkömmliche Logit-Methode. Grün markierte Wörter gelten als vertrauenswürdig, rot markierte als verdächtig. | Bild: Minut et al.
Spilled Energy erkennt die fehlerhaften Antwort-Token "Sydney" und "470" zuverlässiger als die herkömmliche Logit-Methode. Grün markierte Wörter gelten als vertrauenswürdig, rot markierte als verdächtig. | Bild: Minut et al.Bisherige Ansätze setzten darauf, eigene kleine Klassifikatormodelle auf den internen Zuständen eines LLMs zu trainieren, die erkennen sollen, ob eine Antwort korrekt ist. Entscheidend ist laut den Forschern, die Messung auf die exakten Antwort-Token zu beschränken. Bei der Frage nach der Hauptstadt Italiens etwa sei nur das Wort "Rome" oder "Sydney" relevant, nicht der umgebende Satz. Durch diese Lokalisierung verbessere sich die Erkennungsleistung um bis zu 24 Prozent.
Robuste Ergebnisse über neun Benchmarks und mehrere Modelle
Das Team testete seine Methode auf neun etablierten Benchmarks, darunter TriviaQA, HotpotQA, IMDB und Math, sowie auf synthetischen Rechenaufgaben mit 13-stelligen Zahlen. Evaluiert wurden LLaMA-3 8B, Mistral-7B, Gemma (1B und 4B) und Qwen3-8B, jeweils in vortrainierten und instruktionsoptimierten Varianten.
Die Erkennungsgenauigkeit messen die Forscher mit der sogenannten AuROC-Metrik, die angibt, wie gut eine Methode korrekte von falschen Antworten trennen kann. Ein Wert von 50 Prozent entspricht dem Zufall, 100 Prozent wären perfekte Erkennung. Spilled Energy übertraf dabei sowohl die einfache Konfidenz der Ausgabewerte als auch die trainierten Fehlerdetektoren.
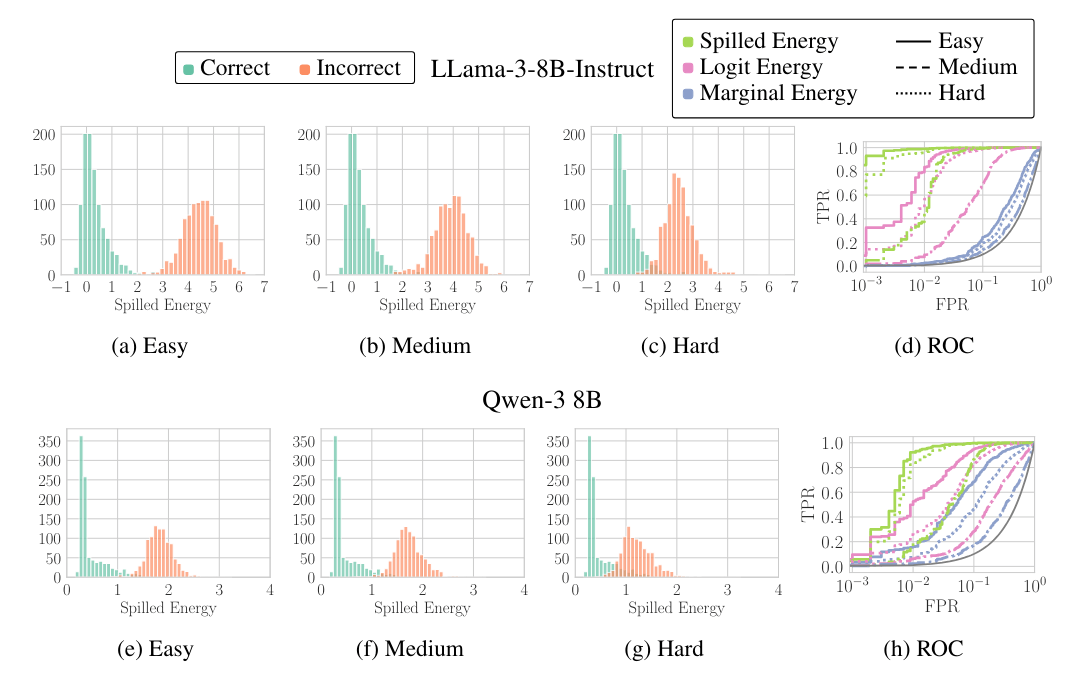 Die Histogramme zeigen, wie sich die Spilled-Energy-Werte für korrekte (grün) und inkorrekte (orange) Antworten verteilen. Je weiter die beiden Farben auseinanderliegen, desto besser erkennt die Methode Fehler. Selbst bei minimalen Abweichungen in der Antwort (Hard) bleiben die Verteilungen gut trennbar. | Bild: Minut et al.
Die Histogramme zeigen, wie sich die Spilled-Energy-Werte für korrekte (grün) und inkorrekte (orange) Antworten verteilen. Je weiter die beiden Farben auseinanderliegen, desto besser erkennt die Methode Fehler. Selbst bei minimalen Abweichungen in der Antwort (Hard) bleiben die Verteilungen gut trennbar. | Bild: Minut et al.Bei Mistral-Instruct erreichte Spilled Energy im Schnitt 77,49 Prozent, verglichen mit 65,56 Prozent für die trainierten Klassifikatoren und 63,44 Prozent für die reine Logit-Konfidenz. Der Ansatz, das Modell einfach selbst zu fragen, ob seine Antwort stimmt, landete mit rund 55 Prozent kaum über Zufallsniveau.
Besonders deutlich zeigte sich der Vorteil bei der Generalisierung über Aufgabentypen hinweg: Trainierte Klassifikatoren fielen bei Anwendung auf neue Datensätze nahezu auf Zufallsniveau. Spilled Energy lieferte ohne jedes Training stabile Ergebnisse.
Instruction Tuning, also die Feinabstimmung eines Modells auf menschliche Anweisungen, verschlechterte die konfidenzbasierte Halluzinationserkennung, vermutlich weil feinabgestimmte Modelle zu Überkonfidenz neigen.
Spilled Energy profitierte dagegen von genau diesem Verfahren. Bei LLaMA-3 stieg die Erkennungsrate von 68,69 auf 73,16 Prozent, bei Mistral von 73,94 auf 77,49 Prozent. Tests mit Gemma zeigten zudem, dass der Ansatz auch über verschiedene Modellgrößen hinweg funktioniert, sowohl bei 1B als auch bei 4B Parametern.
Grenzen bei Satzzeichen und Satzanfängen
Die Forscher räumen Einschränkungen ihrer Methode ein. Spilled Energy produziere gelegentlich Fehlalarme bei nicht-semantischen Token wie Satzzeichen oder Wörtern am Satzanfang. An solchen Stellen verteile sich die Wahrscheinlichkeitsmasse natürlicherweise auf viele plausible nächste Wörter, was die Energiewerte aufblähe. Die korrekte Identifizierung der eigentlichen Antwort-Token sei daher entscheidend.
Spilled Energy könne Halluzinationen nicht verhindern, bietet aber laut den Forschern ein mathematisch fundiertes Werkzeug, um sie während der Textgenerierung zu erkennen. Der Code ist auf GitHub verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.


