Die Forschenden führen diesen Leistungsunterschied auf eine systematische Lücke zwischen dekontextualisierten Quizfragen und den Fähigkeiten zurück, die echte wissenschaftliche Entdeckung erfordert: problembezogenes Kontextverständnis, iterative Hypothesengenerierung und die Interpretation unvollständiger Evidenz.
Bestehende Benchmarks messen das Falsche
Das Problem liegt laut den Forschern in der Konzeption bisheriger Wissenschafts-Benchmarks wie GPQA, MMMU oder ScienceQA. Diese prüfen isoliertes Faktenwissen, das lose mit bestimmten Forschungsgebieten verbunden ist. Wissenschaftliche Entdeckung funktioniert jedoch anders: Sie erfordert iteratives Denken, das Aufstellen und Verfeinern von Hypothesen sowie die Interpretation unvollständiger Beobachtungen.
Um diese Lücke zu schließen, entwickelte das Team den SDE-Benchmark mit 1.125 Fragen in 43 Forschungsszenarien aus vier Domänen: Biologie, Chemie, Materialwissenschaft und Physik. Der entscheidende Unterschied zu bestehenden Tests: Jede Frage ist an ein konkretes Forschungsszenario gebunden, das aus Forschungsprojekten abgeleitet ist. Expertenteams definierten zunächst realistische Forschungsszenarien aus ihrer eigenen Arbeit und entwickelten daraus Fragen, die anschließend von Fachkollegen geprüft wurden.
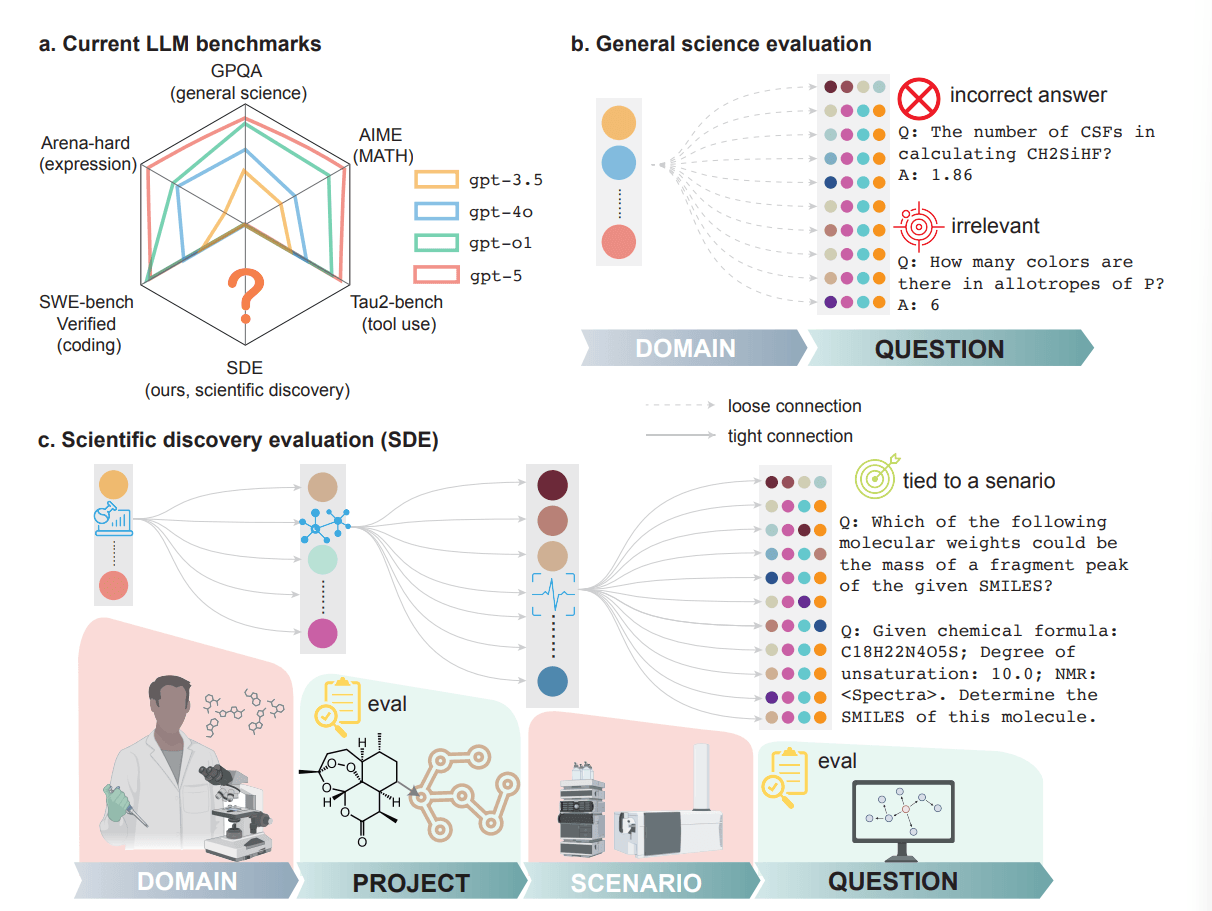 Vom Wissenstest zur Forschungssimulation: Herkömmliche Benchmarks verbinden Fragen nur lose mit Fachgebieten und enthalten teils fehlerhafte oder irrelevante Aufgaben. Das SDE-Framework verknüpft jede Frage eng mit konkreten Forschungsszenarien und Projekten. Die Evaluation erfolgt sowohl auf Fragen- als auch auf Projektebene, wobei LLMs den gesamten Entdeckungszyklus durchlaufen müssen. | Bild: Song et al.
Vom Wissenstest zur Forschungssimulation: Herkömmliche Benchmarks verbinden Fragen nur lose mit Fachgebieten und enthalten teils fehlerhafte oder irrelevante Aufgaben. Das SDE-Framework verknüpft jede Frage eng mit konkreten Forschungsszenarien und Projekten. Die Evaluation erfolgt sowohl auf Fragen- als auch auf Projektebene, wobei LLMs den gesamten Entdeckungszyklus durchlaufen müssen. | Bild: Song et al.Die Szenarien reichen von der Vorhersage chemischer Reaktionen über die Strukturaufklärung mittels NMR-Spektren bis zur Identifikation kausaler Gene in genomweiten Assoziationsstudien. Diese Bandbreite soll abbilden, was Wissenschaftler tatsächlich in ihrer Forschung benötigen.
Große Leistungsunterschiede zwischen Szenarien
Die Ergebnisse zeigen einen generellen Leistungsabfall gegenüber herkömmlichen Benchmarks und zudem extreme Schwankungen zwischen verschiedenen Forschungsszenarien. GPT-5 erreicht bei der Retrosynthese-Planung einen Wert von 0,85, bei der NMR-basierten Strukturaufklärung jedoch nur 0,23. Diese Varianz zieht sich durch alle getesteten Modelle.
Für die Forscher bedeutet das: Benchmarks, die Fragen nur nach Fachgebieten kategorisieren, sind unzureichend. Wissenschaftliche Entdeckung scheitert oft am schwächsten Glied der Kette. Der SDE-Benchmark soll deshalb auch als Nachschlagewerk dienen, das die Stärken und Schwächen von Sprachmodellen in spezifischen Forschungsszenarien aufzeigt.
Skalierung und Reasoning stoßen an Grenzen
Die Studie untersucht auch, ob die üblichen Strategien zur Leistungssteigerung, größere Modelle und mehr Rechenzeit für Reasoning, bei wissenschaftlicher Entdeckung helfen. Die Antwort fällt gemischt aus.
Reasoning verbessert die Leistung grundsätzlich: DeepSeek-R1 übertrifft DeepSeek-V3.1 in den meisten Szenarien, obwohl beide auf demselben Basismodell aufbauen. Bei der Beurteilung von Lipinskis Fünferregel, einer Faustregel zur Vorhersage der oralen Bioverfügbarkeit von Medikamenten, steigt die Genauigkeit durch Reasoning von 0,65 auf 1,00.
Doch die Forscher beobachten auch abnehmende Erträge. Bei GPT-5 bringt eine Steigerung der Reasoning-Anstrengung von "medium" auf "high" kaum noch Verbesserungen. Der Sprung von o3 zu GPT-5 zeigt ebenfalls nur marginale Fortschritte, in acht Szenarien schneidet GPT-5 sogar schlechter ab.
 Abnehmende Erträge bei Skalierung und Reasoning: (a) Mehr Reasoning-Anstrengung verbessert die Genauigkeit zunächst deutlich, stagniert aber zwischen "medium" und "high". (b) Größere Modelle schneiden besser ab, doch der Sprung von o3 zu GPT-5 fällt gering aus. (c) Der direkte Vergleich zeigt: GPT-5 übertrifft o3 nur knapp, in einigen Szenarien schneidet es sogar schlechter ab. | Bild: Song et al.
Abnehmende Erträge bei Skalierung und Reasoning: (a) Mehr Reasoning-Anstrengung verbessert die Genauigkeit zunächst deutlich, stagniert aber zwischen "medium" und "high". (b) Größere Modelle schneiden besser ab, doch der Sprung von o3 zu GPT-5 fällt gering aus. (c) Der direkte Vergleich zeigt: GPT-5 übertrifft o3 nur knapp, in einigen Szenarien schneidet es sogar schlechter ab. | Bild: Song et al.Die Schlussfolgerung der Forscher: Die aktuelle Strategie, die Modellgröße und Test-Time-Compute zu erhöhen, was zuletzt große Fortschritte beim Coding und in der Mathematik brachte, stößt bei wissenschaftlicher Entdeckung an ihre Grenzen.
Top-Modelle machen dieselben Fehler
Ein weiterer Befund: Die besten Modelle verschiedener Anbieter, GPT-5, Grok-4, DeepSeek-R1 und Claude-Sonnet-4.5, zeigen hochkorrelierte Fehlerprofile. In Chemie und Physik liegen erhobene Korrelationskoeffizienten zwischen allen Modellpaaren über 0,8 – das heißt: Die Modelle konvergieren besonders bei den schwierigsten Fragen häufig auf dieselben falschen Antworten.
Die Forscher sehen darin einen Hinweis auf ähnliche Trainingsdaten und Optimierungsziele, nicht auf architektonische Unterschiede. Praktisch bedeutet das: Ensemble-Strategien wie Mehrheitsabstimmungen zwischen verschiedenen Modellen dürften bei den schwierigsten Fragen wenig bringen.
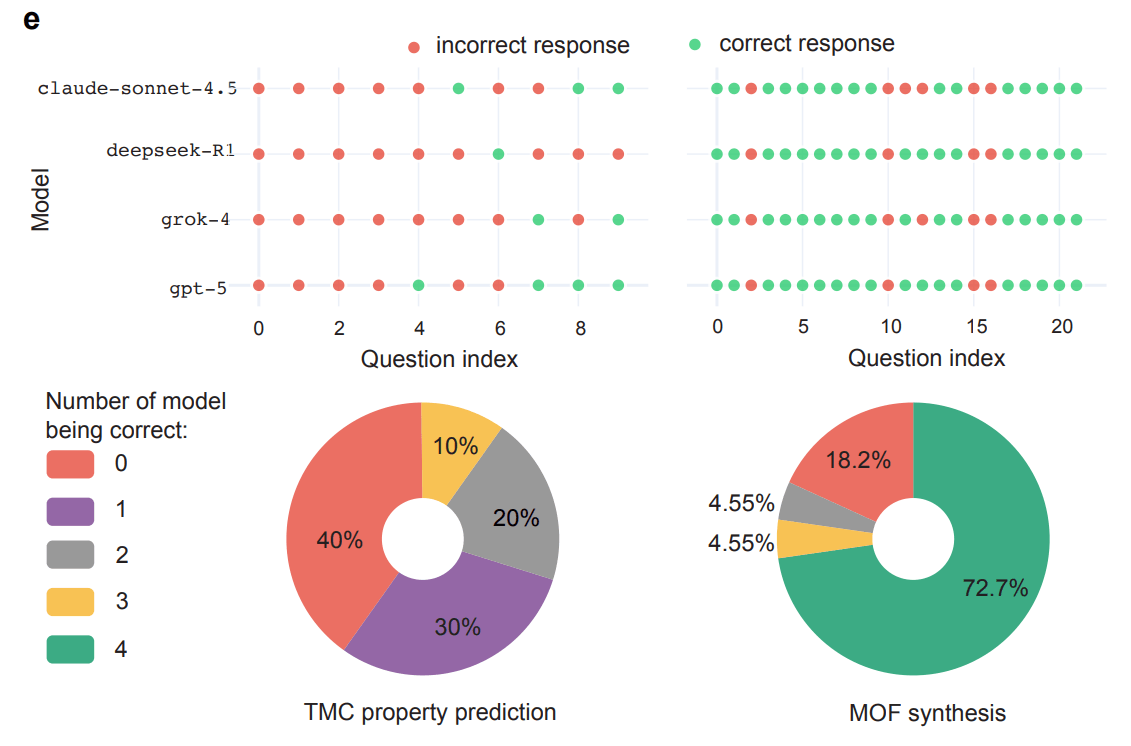 Gemeinsame Fehler von vier Spitzen‑LLMs in zwei chemischen Szenarien. Oben: Jede Spalte steht für eine Frage, jede Zeile für ein Modell; grün = richtig, rot = falsch. Links (TMC property prediction) liegen die Modelle oft gemeinsam falsch, rechts (MOF synthesis) meist gemeinsam richtig, bei einigen Fragen aber ebenfalls alle falsch. Die Donut‑Diagramme unten zeigen, bei wie vielen Fragen 0–4 Modelle korrekt lagen. | Bild: Song et al.
Gemeinsame Fehler von vier Spitzen‑LLMs in zwei chemischen Szenarien. Oben: Jede Spalte steht für eine Frage, jede Zeile für ein Modell; grün = richtig, rot = falsch. Links (TMC property prediction) liegen die Modelle oft gemeinsam falsch, rechts (MOF synthesis) meist gemeinsam richtig, bei einigen Fragen aber ebenfalls alle falsch. Die Donut‑Diagramme unten zeigen, bei wie vielen Fragen 0–4 Modelle korrekt lagen. | Bild: Song et al.Um diese Schwachstellen zu isolieren, erstellte das Team ein Subset namens SDE-hard mit 86 besonders schwierigen Fragen. Alle Standardmodelle erreichen dort weniger als 0,12 Genauigkeit. Einzig GPT-5-pro, das zwölfmal teurer ist, kommt auf 0,224 und beantwortet neun Fragen korrekt, an denen alle anderen scheitern.
Projektebene offenbart weitere Lücken
Neben der Fragen-Ebene evaluiert das SDE-Framework auch die Leistung auf Projektebene. Dabei durchlaufen die Modelle einen echten wissenschaftlichen Entdeckungszyklus: Sie müssen Hypothesen aufstellen, Experimente durchführen und die Ergebnisse interpretieren, um ihre Hypothesen zu verfeinern.
Die acht untersuchten Projekte reichen von Proteindesign und Gen-Editing über Retrosynthese und Moleküloptimierung bis zur symbolischen Regression. Das zentrale Ergebnis: Kein einzelnes Modell dominiert alle Projekte. Die Führung wechselt je nach Aufgabe.
 Durchschnittliche Genauigkeit über alle 43 Forschungsszenarien: GPT-5 führt mit 0,658, gefolgt von Claude-Sonnet-4.5 und o3. Die Unterschiede zwischen den Top-Modellen sind gering, ältere Modelle wie GPT-4o und Claude-Sonnet-4 fallen deutlich ab. | Bild: Song et al.
Durchschnittliche Genauigkeit über alle 43 Forschungsszenarien: GPT-5 führt mit 0,658, gefolgt von Claude-Sonnet-4.5 und o3. Die Unterschiede zwischen den Top-Modellen sind gering, ältere Modelle wie GPT-4o und Claude-Sonnet-4 fallen deutlich ab. | Bild: Song et al.Überraschend ist auch, dass gute Fragen-Leistung nicht automatisch gute Projekt-Leistung bedeutet. Bei der Optimierung von Übergangsmetallkomplexen finden die Modelle gpt-5, deepseek-R1 und claude-sonnet-4.5 optimale Lösungen aus Millionen von Möglichkeiten, obwohl sie bei den zugehörigen Wissensfragen schlecht abschneiden. Umgekehrt versagen Modelle bei der Retrosynthese-Planung trotz guter Fragen-Leistung, weil die vorgeschlagenen Synthesewege in der Praxis nicht funktionieren.
Die Forscher deuten das so: Entscheidend ist nicht nur möglichst präzises Fachwissen, sondern vor allem die Fähigkeit, in einem großen Lösungsraum systematisch viele Kandidaten auszuprobieren und dabei auch vielversprechende Ansätze zu finden, die man nicht von Anfang an gezielt angesteuert hat.
KI-Modelle sind weit entfernt von wissenschaftlicher Superintelligenz, aber dennoch nützlich
Die Studie kommt zu dem klaren Ergebnis, dass alle aktuellen Sprachmodelle noch weit von einer allgemeinen wissenschaftlichen "Superintelligenz" entfernt sind. Zugleich zeigt sie, dass LLMs in vielen konkreten Projekten bereits beachtliche Leistungen erbringen: Sie können in Kombination mit spezialisierten Tools und menschlicher Aufsicht Experimente oder Simulationen planen, ausführen und auswerten, große Suchräume effizient erkunden und dabei durch zielgerichtete wie auch zufallsgetriebene Exploration zu neuen, vielversprechenden Kandidaten gelangen.
Die Forscher empfehlen, den Fokus von reiner Skalierung auf gezieltes Training für Problemformulierung und Hypothesengenerierung zu verlagern. Außerdem sei eine Diversifizierung der Pre-Trainingsdaten nötig, um die gemeinsamen Fehlerprofile zu reduzieren.
Weitere Empfehlungen umfassen die Integration von Tool-Nutzung in das Training und die Entwicklung von Reinforcement-Learning-Strategien, die speziell auf wissenschaftliches Reasoning ausgerichtet sind. Die aktuellen Optimierungen für Coding und Mathematik übertragen sich offenbar nicht automatisch auf wissenschaftliche Entdeckung.
Das Framework und die Benchmark-Daten sollen als Grundlage dienen, um die Entwicklung von Sprachmodellen in Richtung wissenschaftlicher Entdeckung voranzutreiben. Die Studie deckt derzeit nur vier Domänen ab, Fachgebiete wie Geowissenschaften, Sozialwissenschaften oder Ingenieurwesen fehlen noch, doch die modulare Architektur erlaubt eine spätere Erweiterung. Das Team hat sowohl den Code für die Fragen-Evaluation als auch die Datensätze für die Projekt-Ebene öffentlich zugänglich gemacht.
Vor wenigen Tagen stellte OpenAI mit FrontierScience einen eigenen Benchmark vor, der KI-Leistung in der Wissenschaft jenseits einfacher Frage-Antwort-Tests messen soll. Das Ergebnis fällt ähnlich aus: Quiz-Wissen ist nicht gleich Forschungskompetenz.

