“What we found is that these AI agents can do something that was previously very difficult: starting from free text (like an anonymized interview transcript) they can work their way to the full identity of a person,” Simon Lermen, a co-author of the paper, told Ars. “This is a pretty new capability; previous approaches on re-identification generally required structured data, and two datasets with a similar schema that could be linked together.”
Unlike those older pseudonymity-stripping methods, Lermen said, AI agents can browse the web and interact with it in many of the same ways humans do. They can use reasoning to match potential individuals. In one experiment, the researchers looked at responses given in a questionnaire Anthropic took about how various people use AI in their daily lives. Using the information taken from answers, the researchers were able to positively identify 7 percent of 125 participants.
End-to-end deanonymization from a single interview transcript (with details altered to protect the subject’s identity). An LLM agent extracted structured identity signals from a conversation, autonomously searched the web to identify a candidate individual, and verified the candidate matched all extracted claims.
End-to-end deanonymization from a single interview transcript (with details altered to protect the subject’s identity). An LLM agent extracted structured identity signals from a conversation, autonomously searched the web to identify a candidate individual, and verified the candidate matched all extracted claims.
![How did you use Al tools in a recent research project? A: I work in biology, on research related to [research topic]. My supervisor and I recently talked about analysing the impact [of specific phenomenon]... My background is in physical science... A: I used Al tools frequently... for writing [specific library] code 2nd collum Profile: • Computational biology, [subfield] • Education: physical science background • Likely PhD student or postdoc • Tools: Python, [specific library] • British English ("analysing") → UK or Commonwealth Third collumn: PhD Student in Biology, [University], UK • Research subfield 8[bioRxiv preprint] • [Research methodology] • PhD student @[University profile] v UK-based • Using [specific library] in • [GitHub repo]](https://cdn.arstechnica.net/wp-content/uploads/2026/03/results-from-questionaire.jpg)
In a second experiment, the researchers gathered comments made in 2024 from the r/movies subreddit and at least one of five smaller communities: r/horror, r/MovieSuggestions, r/Letterboxd, r/TrueFilm, and r/MovieDetails. The results showed that the more movies a candidate discussed, the easier it was to identify them. An average of 3.1 percent of users sharing one movie could be identified with a 90 percent precision, and 1.2 percent of them at a 99 percent precision. With five to nine shared movies, 90 percent and 99 percent precision rose to 8.4 percent and 2.5 percent of users, respectively. More than 10 shared movies bumped the percentage to 48.1 percent and 17 percent.
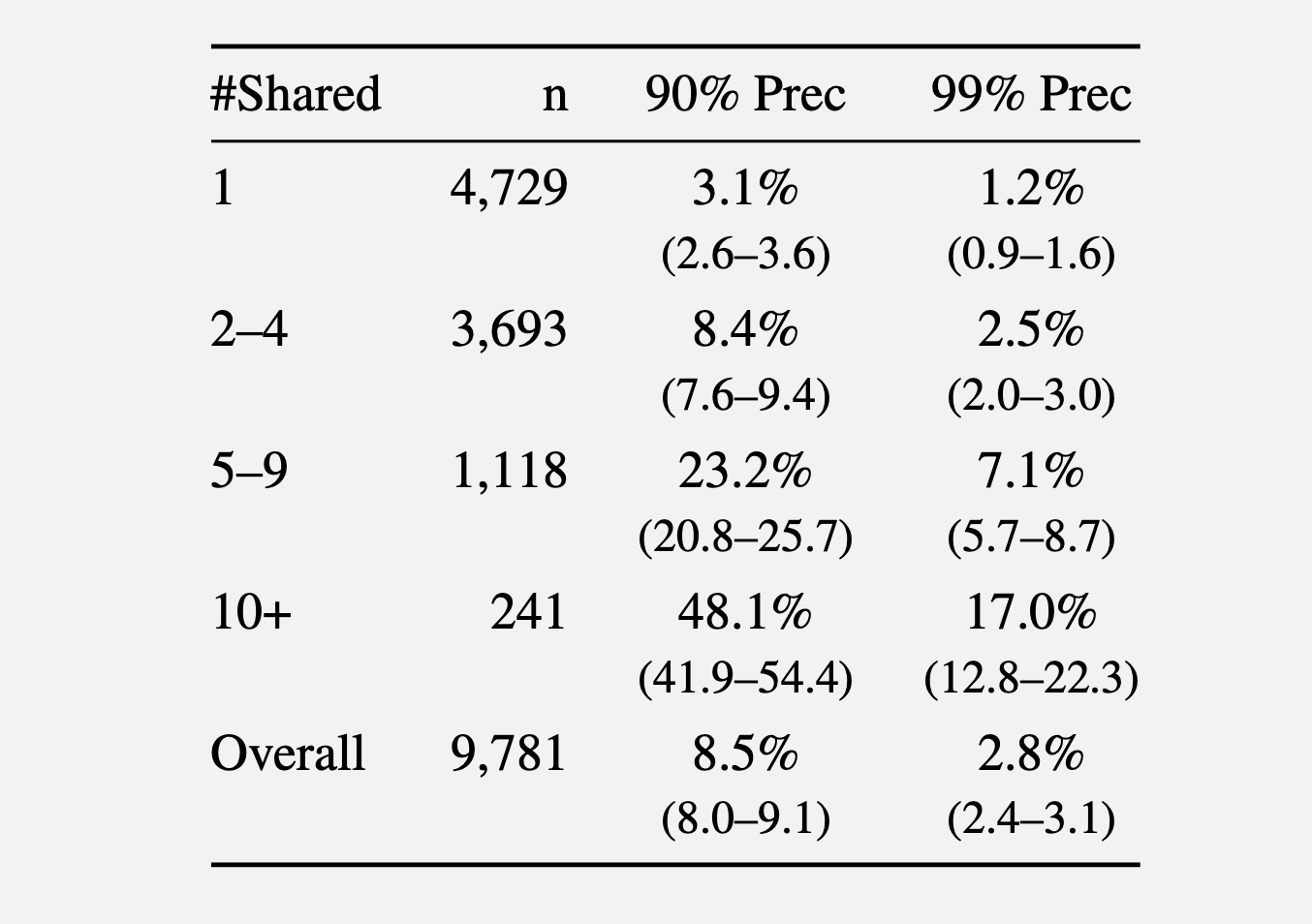
Recall at various precision thresholds.
Recall at various precision thresholds.
In a third experiment, the researchers took Reddit datasets that used the technique in the Netflix prize attack research to ID users. The researchers added 5,000 users from the Netflix dataset and added another 5,000 “distraction” identities of people not in the results. They then added to the list of 10,000 candidate profiles 5,000 query distractors comprising users who appear only in a query set, with no true match in the candidate pool.

