Während in Papers oft Agenten mit Dutzenden oder Hunderten ReAct-Schritten oder komplexen Multi-Agent-Szenarien im Mittelpunkt stehen, begrenzen produktive Systeme ihre Agenten streng: 68 Prozent der in der Studie erfassten produktiven Agenten führen höchstens zehn Schritte aus, bevor ein Mensch eingreifen muss, bei fast der Hälfte (47 Prozent) sind es sogar weniger als fünf.
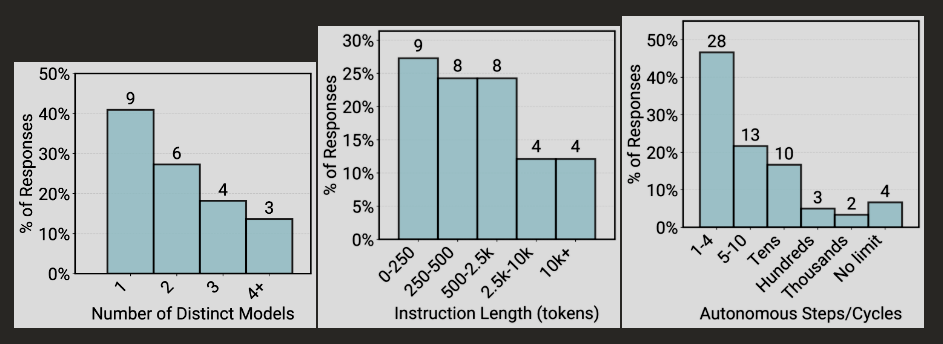 Komplexität produktiver KI-Agenten: Viele Systeme nutzen nur ein einzelnes Modell, eher kurze bis mittellange Systemprompts und bis zu zehn autonome Schritte, bevor Menschen eingreifen. | Bild: Pan et al.
Komplexität produktiver KI-Agenten: Viele Systeme nutzen nur ein einzelnes Modell, eher kurze bis mittellange Systemprompts und bis zu zehn autonome Schritte, bevor Menschen eingreifen. | Bild: Pan et al.Praktiker bevorzugen nach eigenen Angaben "einfache, kontrollierbare Ansätze". 70 Prozent der untersuchten Teams verlassen sich auf Standard-Modelle ("off-the-shelf") und verzichten auf aufwendiges Fine-Tuning der Modellgewichte. Reinforcement Learning spielt in den Interviews praktisch keine Rolle. Stattdessen fließt der Aufwand in weitgehend manuelles Prompt-Engineering.
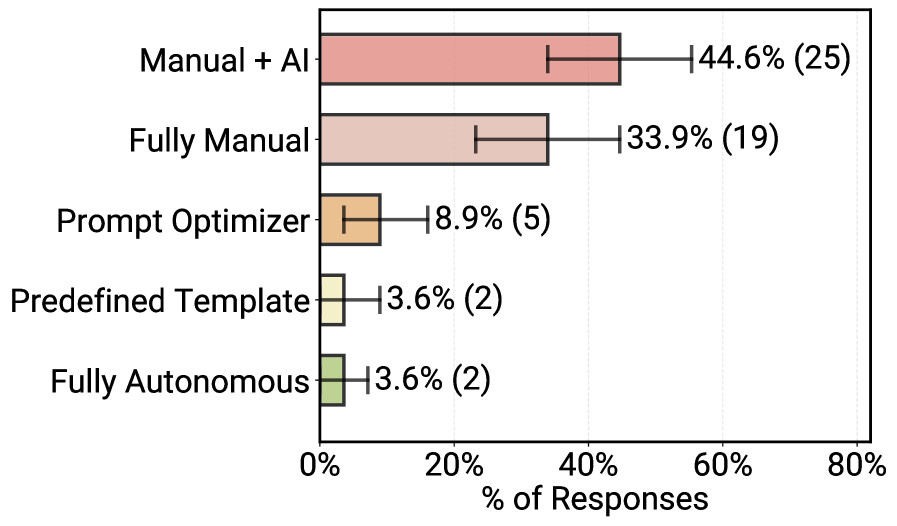 Prompt-Erstellung in Unternehmen: Handarbeit dominiert, unterstützt durch LLMs – automatische Promptoptimierung und vollautonome Prompt-Generierung bleiben die Ausnahme. | Bild: Pan et al.
Prompt-Erstellung in Unternehmen: Handarbeit dominiert, unterstützt durch LLMs – automatische Promptoptimierung und vollautonome Prompt-Generierung bleiben die Ausnahme. | Bild: Pan et al.Erste Schritte hin zu mehr Autonomie sind dennoch zu erkennen. Einige Teams setzen Planungs- oder Routingagenten ein, die eingehende Anfragen analysieren und an spezialisierte Unteragenten weiterleiten. Ein anderes trennt Generator- und Verifier-Agent und lässt letzteren Antworten systematisch prüfen.
Produktivität schlägt Geschwindigkeit
Unternehmen führen KI-Agenten laut Studie in erster Linie aus Effizienzgründen ein. 72,7 Prozent der Teams mit produktiven Systemen nennen "Produktivitätssteigerung" als Hauptmotiv, 63,6 Prozent wollen die von Menschen aufgewendeten Stunden reduzieren, 50 Prozent gezielt Routinearbeit automatisieren. Verbesserte Kundenzufriedenheit erreicht 37,9 Prozent, das Etikett "neue Technologie" 33,3 Prozent. Risikominderung landet mit 12,1 Prozent am Ende der Liste. Ein Grund dafür ist, dass Zeitgewinne und eingesparte Arbeitsstunden sich relativ einfach messen lassen, Effekte auf Stabilität oder Risiko dagegen kaum.
Entsprechend locker sind viele Latenzanforderungen. Für 41,5 Prozent der produktiven Agenten sind Antwortzeiten im Minutenbereich akzeptabel, 26,4 Prozent zielen auf Sekunden, nur 7,5 Prozent verlangen subsekundäre Reaktionen; 17 Prozent der befragten Teams haben noch gar kein festes Latenzbudget.
In den Interviews heißt es dazu, dass Agenten überwiegend Aufgaben übernehmen, die bisher Stunden oder Tage menschlicher Arbeit erforderten. Ein System, das für eine komplexe Recherche fünf Minuten benötigt, gilt vor diesem Hintergrund als ausreichend schnell. Asynchrone Arbeitsabläufe – etwa nächtliche Analysen oder periodische Reports – verstärken diesen Effekt. Latenzprobleme melden primär Teams, die Sprach- oder Chatagenten mit dialogischer Interaktion entwickeln. Dort schlägt sich jede Verzögerung unmittelbar in der Nutzererfahrung nieder.
Agenten dienen Menschen – selten Maschinen
Trotz des Hypes um "AI-to-AI"-Ökosysteme richten sich 92,5 Prozent der produktiven Systeme primär an Menschen, nur 7,5 Prozent an andere Agenten oder Software. In etwas mehr als der Hälfte der Fälle sind die Nutzer interne Mitarbeitende, in 40,3 Prozent externe Kundinnen und Kunden.
Viele Organisationen halten Agenten bewusst zunächst im internen Einsatz, um Fehler besser abfangen zu können und Fachpersonal als letzte Instanz zu behalten. Agenten agieren überwiegend als Werkzeuge zur Unterstützung von Domänenexpertinnen und -experten, während Menschen in der Regel die endgültige Entscheidung und Verifikation übernehmen.
Eigenentwicklungen schlagen Frameworks
Eine weitere Auffälligkeit betrifft die Softwarearchitektur. In der breiten Umfrage gaben rund 60 Prozent der Befragten an, Frameworks wie LangChain oder CrewAI zu nutzen. In den detaillierten Fallstudien mit produktiven Systemen zeichnet sich jedoch ein anderes Bild ab: 85 Prozent der Teams bauen ihre Agenten-Anwendungen von Grund auf neu und verzichten auf Drittanbieter-Frameworks.
Als Gründe nennen die Interviewten Kontrolle und Flexibilität. Frameworks führten oft zu unnötiger Komplexität ("dependency bloat") und erschwertem Debugging. Eigene Implementierungen der Kernschleifen per direkter API-Aufrufe seien für Produktionsumgebungen leichter zu überblicken und zu warten.
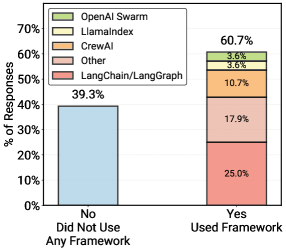 Nutzung von Agentenframeworks: Etwa 60 Prozent der befragten Teams verwenden Frameworks wie LangChain, CrewAI oder Alternativen, rund 40 Prozent entwickeln ohne dedizierte Framework-Unterstützung. | Bild: Pan et al.
Nutzung von Agentenframeworks: Etwa 60 Prozent der befragten Teams verwenden Frameworks wie LangChain, CrewAI oder Alternativen, rund 40 Prozent entwickeln ohne dedizierte Framework-Unterstützung. | Bild: Pan et al.Die Kontrollflüsse bleiben dabei meist statisch. 80 Prozent der in den Interviews analysierten Agenten folgen festen Workflows mit klar definierten Subtasks. Ein Versicherungsagent etwa durchläuft immer die gleiche Sequenz aus Deckungsprüfung, medizinischer Notwendigkeitsprüfung und Risikoidentifikation. Innerhalb dieser Teilaufgaben besitzt der Agent gewisse Autonomie, wobei Ziel und erwarteter Output jedes Subschritts fest vorgegeben sind.
Zuverlässigkeit ist die größte Hürde
Das Hauptproblem bei der Entwicklung bleibt die Zuverlässigkeit ("Reliability"). Da KI-Modelle nicht deterministisch arbeiten, ist es schwierig, ihre Korrektheit sicherzustellen. In einer Rangfrage zu Entwicklungshürden nennen die Befragten "Core Technical Performance" – also Robustheit, Zuverlässigkeit, Skalierbarkeit, Latenz und Ressourceneffizienz – am häufigsten als größte Herausforderung.
Themen wie Transparenz, Governance oder regulatorische Compliance folgen mit deutlichem Abstand. Sicherheits- und Datenschutzfragen werden nicht verharmlost, erscheinen in den beschriebenen, oft stark eingehegten Szenarien jedoch als beherrschbar.
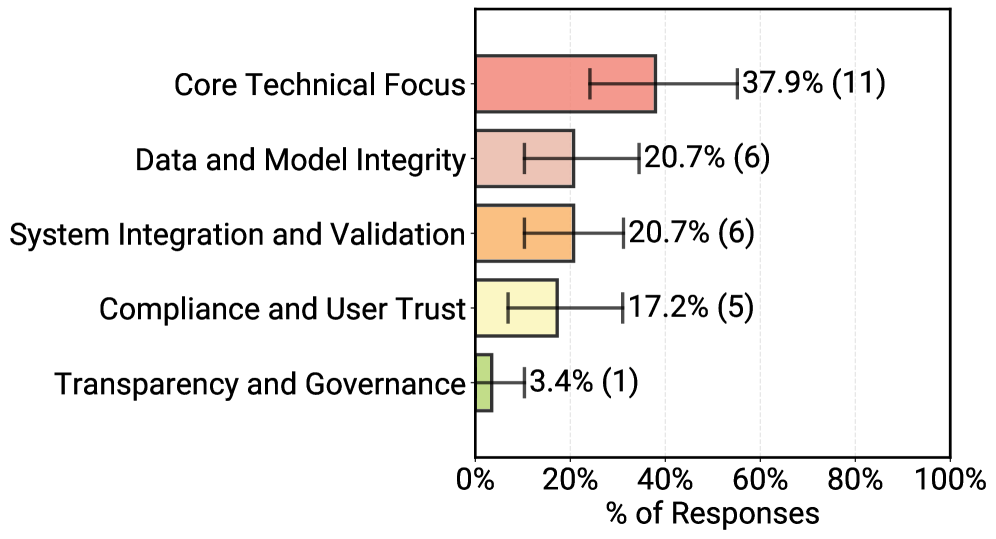 Wichtigste Herausforderungen beim Aufbau produktiver KI-Agenten: Knapp 38 Prozent der Teams sehen technische Zuverlässigkeit und Performance als größtes Problem, deutlich vor Daten- und Modellqualität, Systemintegration, Compliance und Governance-Fragen. | Bild: Pan et al.
Wichtigste Herausforderungen beim Aufbau produktiver KI-Agenten: Knapp 38 Prozent der Teams sehen technische Zuverlässigkeit und Performance als größtes Problem, deutlich vor Daten- und Modellqualität, Systemintegration, Compliance und Governance-Fragen. | Bild: Pan et al.Die Evaluationspraxis spiegelt diese Unsicherheit wider. 74 Prozent der produktiven Agenten werden primär durch Menschen bewertet ("Human-in-the-loop"). 52 Prozent nutzen zusätzlich "LLM-as-a-Judge"-Verfahren, bei denen eine KI die Ausgabe einer anderen KI bewertet – allerdings fast immer in Kombination mit menschlicher Überprüfung.
Typische Muster in den Fallstudien: Ein LLM bewertet jede Agentenantwort mit einem Score. Liegt dieser unter einem Schwellwert, geht der Fall an menschliche Prüferinnen und Prüfer. Zusätzlich werden auch als korrekt bewertete Antworten stichprobenartig kontrolliert, um Modell- und Promptdrift zu erkennen.
Da Agenten oft sehr spezifische Aufgaben übernehmen, existieren selten öffentliche Benchmarks. 75 Prozent der befragten Teams evaluieren ihre Systeme ohne formale Benchmarks und verlassen sich stattdessen auf A/B-Tests oder direktes Nutzerfeedback.
Bei der Modellwahl dominieren proprietäre Frontier-Modelle wie die GPT-Serie von OpenAI oder Claude von Anthropic. Open-Source-Modelle kommen in den Fallstudien überwiegend dann zum Einsatz, wenn strikte Regularien oder enorme Kosten bei hohen Volumina dies erzwingen. Auch hier zeigt sich der Pragmatismus der Teams: Sie wählen in der Regel das leistungsfähigste Modell, das unter den jeweiligen Kosten- und Regulierungsbedingungen einsetzbar ist.
Forschung trifft Praxis: Warum der Agenten-Hype noch an der Realität vorbeigeht
Die MAP-Studie ist explizit als technische Bestandsaufnahme gedacht und grenzt sich von Management-Umfragen ab. Sie zeigt, dass viele Themen, die in Forschungspapieren und Produktankündigungen dominieren – etwa komplexe Multi-Agent-Szenarien, umfangreiche Post-Training-Verfahren oder automatisierte Prompt-Optimierung – in den untersuchten produktiven Systemen bislang deutlich seltener zu finden sind; stattdessen dominieren einfache, kontrollierbare Architekturen.
Erfolgreiche Teams setzen stattdessen auf einfache, kontrollierbare Architekturen: wenige Schritte, klare Workflows, menschliche Aufsicht, weitgehend manuelle Prompts und Frontier-Modelle ohne umfangreiches Post-Training. Die Autor:innen warnen, dass Forschung, die diese Produktionsrealitäten ignoriert, Gefahr läuft, am Bedarf der Praxis vorbeizuentwickeln.
Substanzlos ist der Agenten-Hype dennoch nicht. Laut den befragten Teams sind Produktivitäts- und Effizienzgewinne der wichtigste Grund für den Einsatz ihrer Agenten, etwa in Bereichen wie Versicherungs‑, HR‑ oder Analyse‑Workflows. Die Systeme übernehmen dort Teile der routinemäßigen Wissensarbeit, während Fachpersonal die komplexeren Entscheidungen und die finale Prüfung trifft. Konkrete Messzahlen zu Produktivitätszuwächsen berichtet die MAP-Studie allerdings nicht, sondern wertet an dieser Stelle vor allem die von den Praktikern genannten Vorteile aus.
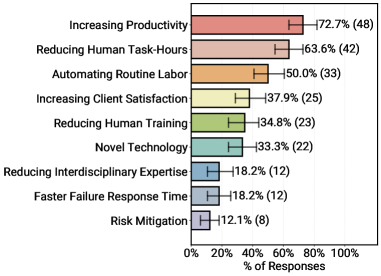 Gründe für den Einsatz von KI-Agenten: Im Vordergrund stehen Produktivitätsgewinne, Zeiteinsparungen und die Automatisierung von Routineaufgaben – Risikominderung und schnellere Fehlerreaktion spielen dagegen nur eine Nebenrolle. | Bild: Pan et al.
Gründe für den Einsatz von KI-Agenten: Im Vordergrund stehen Produktivitätsgewinne, Zeiteinsparungen und die Automatisierung von Routineaufgaben – Risikominderung und schnellere Fehlerreaktion spielen dagegen nur eine Nebenrolle. | Bild: Pan et al.Die "Agency" wächst unbemerkt
Auch wenn die Studie zeigt, dass produktive Agenten heute meist noch stark begrenzte, gut kontrollierte Systeme sind, sollte man die wachsende Handlungsfähigkeit ('Agency') moderner KI-Modelle nicht unterschätzen. Immer häufiger entscheiden KI-Systeme während der Laufzeit eigenständig, ob sie etwa eine Internetsuche initiieren oder Code generieren, um in ein Bild hineinzuzoomen, und erweitern so ihre Einsatzmöglichkeiten deutlich.
Für Nutzerinnen und Nutzer bleibt diese agentische Arbeitsweise meist unsichtbar, etwa wenn sie direkt mit Google Gemini oder ChatGPT arbeiten. Oft merken sie erst an längeren Antwortzeiten, die Minuten statt Sekunden betragen können, dass im Hintergrund ein komplexerer Agenten-Workflow abläuft. In diesem Sinne dürfte agentische KI sogar weiter verbreitet sein, als bisher angenommen – etwa in Form von Deep-Research-Funktionen.
Deepmind-CEO Demis Hassabis geht davon aus, dass diese Form agentischer KI im kommenden Jahr verlässlicher wird, und damit einen aktuellen zentralen Kritikpunkt adressiert.


