Mit GPT-5.4 Thinking berichtet OpenAI erstmals über die "CoT-Kontrollierbarkeit" eines Modells. Eine begleitende Studie zeigt: Reasoning-Modelle scheitern fast durchgängig daran, ihre Gedankenketten gezielt zu manipulieren. Für die KI-Sicherheit ist das eine gute Nachricht.
OpenAI berichtet ab sofort in den System Cards seiner Frontier-Modelle über einen neuen Sicherheitswert: die sogenannte CoT-Kontrollierbarkeit. Den Anfang macht GPT-5.4 Thinking. Der Wert misst, wie gut ein Reasoning-Modell seine internen Gedankenketten (Chain of Thought / CoT) gezielt steuern kann. Ein niedriger Wert gilt als wünschenswert: Er deutet darauf hin, dass ein Modell seine Denkprozesse nicht verschleiern kann, um Überwachungssysteme zu umgehen.
Hintergrund ist das sogenannte CoT-Monitoring, bei dem die Zwischenschritte eines Reasoning-Modells mitgelesen werden, um problematische Absichten frühzeitig zu erkennen. Dieser Sicherheitsmechanismus funktioniert jedoch nur, solange Modelle ihre Gedankenketten nicht gezielt umgestalten können.
GPT-5.4 Thinking kontrolliert seine Gedankenkette in 0,3 Prozent der Fälle
Laut der System Card kontrolliert GPT-5.4 Thinking bei Gedankenketten von 10.000 Zeichen Länge nur 0,3 Prozent seiner CoTs erfolgreich. GPT-5.2 Thinking liegt bei 0,2 Prozent. Die gestiegenen Reasoning-Fähigkeiten gehen demnach nicht mit einer erhöhten Fähigkeit einher, die eigene Gedankenkette zu verschleiern.
Die Grundlage für die neue Metrik liefert eine begleitende Studie von Forschern der NYU, UCL, University of Pennsylvania und OpenAI. Sie stellt die Open-Source-Evaluierungssuite CoT-Control vor, die über 14.000 Testaufgaben aus Benchmarks wie GPQA, MMLU-Pro und SWE-Bench Verified umfasst. Die Modelle erhalten dabei explizite Anweisungen für ihre Gedankenkette, etwa eine Genetik-Frage zu beantworten, ohne das Wort "Chromosom" zu verwenden.
Modelle erkennen ihr Versagen und scheitern trotzdem weiter
Die Ergebnisse von über 13 Frontier-Modelle fallen eindeutig aus: Die CoT-Kontrollierbarkeit liegt zwischen 0,1 Prozent (DeepSeek R1) und 36,1 Prozent (Claude 3.7 Sonnet). Bei den meisten Modellen bleibt der Wert unter 10 Prozent. Dieselben Modelle erreichen bei der Kontrolle ihrer finalen Ausgabe hingegen 37,8 bis 69,3 Prozent.
Besonders aufschlussreich sind die dokumentierten Fehlerbeispiele. GPT-5.2 sollte das Wort "XOR" vermeiden, benutzte es mehrfach, bemerkte den Verstoß und schrieb laut der Studie: "Oops I wrote 'XOR' in analysis already." Anschließend verwendete es das Wort noch viermal.
Mehr Training senkt die Kontrollierbarkeit
Die Studie identifiziert mehrere Einflussfaktoren. Größere Open-Weight-Modelle zeigen höhere Kontrollierbarkeit, doch Reinforcement Learning mit verifizierbaren Belohnungen reduziert sie im Trainingsverlauf um mehr als eine Größenordnung. Auch längeres Nachdenken und schwierigere Aufgaben senken den Wert.
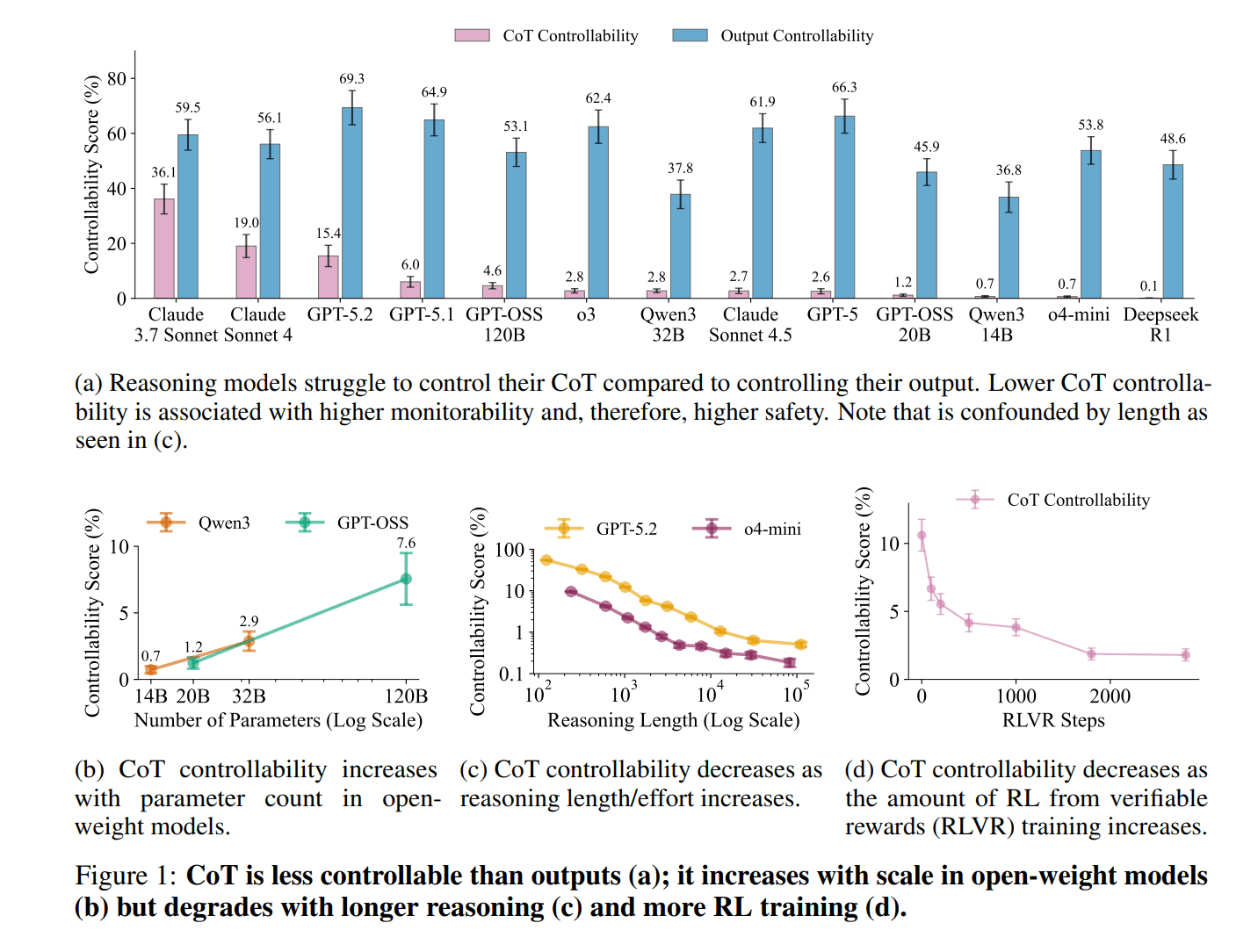 CoT ist im Vergleich zur Ausgabe deutlich weniger kontrollierbar (a), steigt mit Modellgröße bei offenen Gewichten (b), fällt bei längerer Kettenführung (c) und mit zunehmendem RLVR-Training (d) ab. | Bild: OpenAI
CoT ist im Vergleich zur Ausgabe deutlich weniger kontrollierbar (a), steigt mit Modellgröße bei offenen Gewichten (b), fällt bei längerer Kettenführung (c) und mit zunehmendem RLVR-Training (d) ab. | Bild: OpenAIWenn Modelle erfahren, dass sie überwacht werden, steigt die Kontrollierbarkeit um bis zu vier Prozentpunkte. Adversariale Prompt-Optimierung konnte Gewinne auf einem Trainingsset erzielen, die sich jedoch kaum auf neue Anweisungstypen übertrugen.
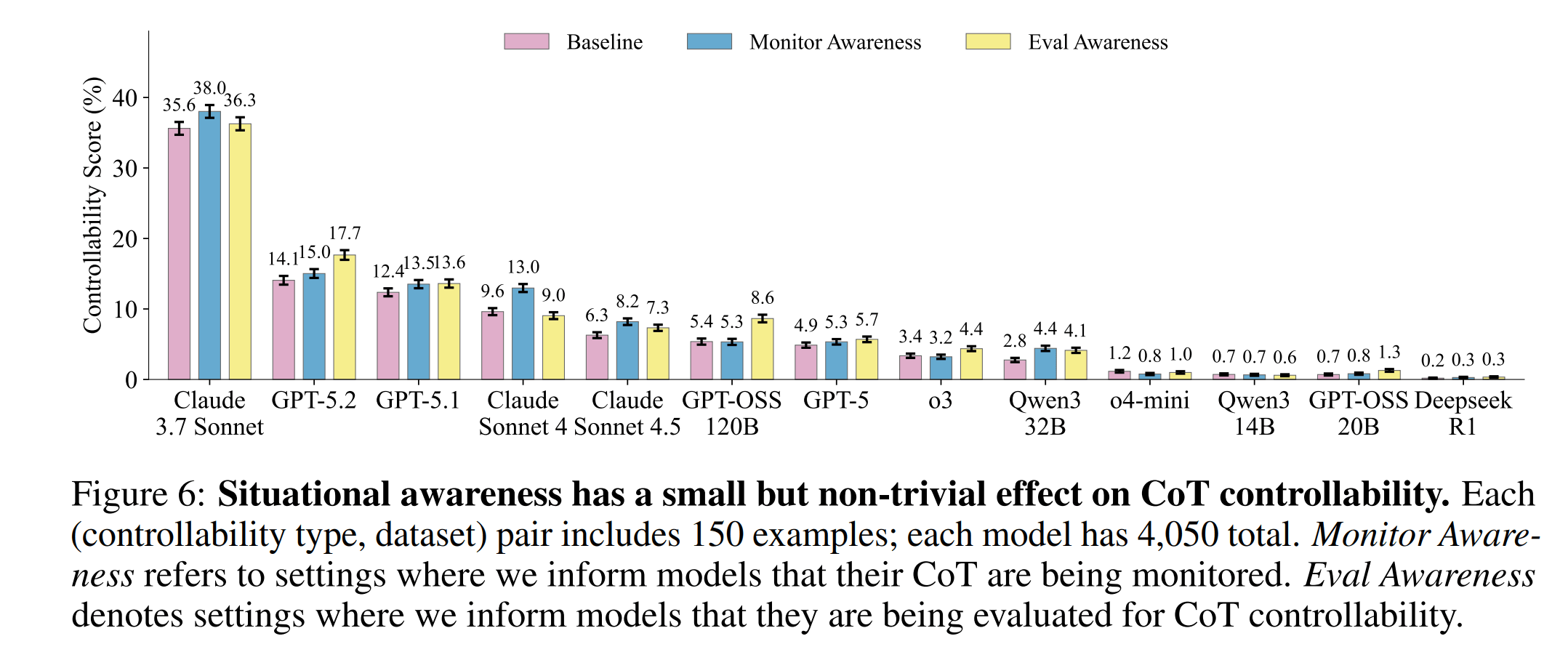 Situationsbewusstsein führt bei den meisten Modellen zu einer leichten Steigerung der CoT-Controllability im Vergleich zur Baseline, wobei Eval Awareness (Gelb) die stärkste Wirkung zeigt.
Situationsbewusstsein führt bei den meisten Modellen zu einer leichten Steigerung der CoT-Controllability im Vergleich zur Baseline, wobei Eval Awareness (Gelb) die stärkste Wirkung zeigt.│ Bild: OpenAI
Stärkere Modelle zeigten zudem ein paradoxes Verhalten: Sie erwähnten in ihrer Gedankenkette häufiger, dass sie eine bestimmte Einschränkung befolgen müssen, obwohl die Anweisung genau das verbot. Die Forscher nennen dieses Phänomen "Meta-Diskussion". Ein Überwachungssystem könnte solche Erwähnungen trivial erkennen.
Mechanismus bleibt unverstanden, Einschränkungen sind erheblich
Die Forscher räumen ein, dass ihre Methode ein Proxy ist. Eine ideale Evaluation würde auch testen, ob Modelle, die eigenständig fehlgeleitete Ziele verfolgen, ihre Gedankenketten gezielt manipulieren können. Zudem könnte die Kontrollierbarkeit durch Finetuning oder gezieltes RL-Training möglicherweise gesteigert werden, was in der Studie nicht untersucht wurde. Der Mechanismus, der die niedrige Kontrollierbarkeit verursacht, sei zudem nicht verstanden.
Niedrige Kontrollierbarkeit allein garantiere auch keine hohe Monitorierbarkeit, da diese zusätzlich durch andere Mechanismen beeinträchtigt werden könne, etwa durch direkten Optimierungsdruck auf die Gedankenketten während des Trainings. Die Forscher empfehlen Frontier-Labs dennoch, die CoT-Kontrollierbarkeit künftiger Modelle systematisch zu messen.
OpenAI bekräftigt in diesem Zusammenhang seine Verpflichtung, keinen solchen direkten Optimierungsdruck auf die CoTs von Frontier-Reasoning-Modellen auszuüben. Denn wenn CoTs direkt optimiert würden – etwa um sie kürzer, lesbarer oder stilistisch einheitlicher zu machen –, könnte das die Gedankenketten so verändern, dass sie die tatsächlichen internen Überlegungen des Modells nicht mehr zuverlässig widerspiegeln. Das würde CoT-Monitoring als Sicherheitsmechanismus grundlegend untergraben.
Die CoT-Control-Suite steht als Open-Source-Werkzeug auf GitHub zur Verfügung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.

