In einem neuen Papier erklärt Google Deepmind, wie es die Risiken auf dem Weg zur Artificial General Intelligence (AGI) eindämmen will.
In einem umfassenden Strategiepapier legt Deepmind dar, wie das Unternehmen die Entwicklung einer sicheren künstlichen allgemeinen Intelligenz (AGI) gestalten will. Das Ziel: Systeme zu entwickeln, die bei den meisten kognitiven Aufgaben mindestens so leistungsfähig sind wie Menschen – ohne dabei neue Risiken zu schaffen. Im Fokus stehen insbesondere der Schutz vor Missbrauch und die Vermeidung von Fehlausrichtung.
Deepmind geht davon aus, dass die derzeit dominanten KI-Technologien – speziell maschinelles Lernen auf Basis neuronaler Netze – weiterhin der maßgebliche Entwicklungsansatz bleiben werden. Das Unternehmen rechnet mit der Möglichkeit, dass KI-Systeme künftig menschliche Fähigkeiten übertreffen könnten.
"Im derzeitigen Paradigma (weit gefasst) sehen wir keine grundlegenden Hürden, die KI-Systeme auf menschliches Leistungsniveau begrenzen würden", schreibt das Forschungsteam in dem Papier An Approach to Technical AGI Safety & Security (PDF).
Anzeige
THE DECODER Newsletter
Die wichtigen KI-News direkt ins E-Mail-Postfach.
✓ 1x wöchentlich
✓ kostenlos
✓ jederzeit kündbar
In Kombination mit sogenannten agentischen Fähigkeiten könnten sie dann eigenständig handeln, planen und Entscheidungen treffen – mit weitreichenden Auswirkungen auf Gesundheit, Bildung, Wissenschaft und Gesellschaft.
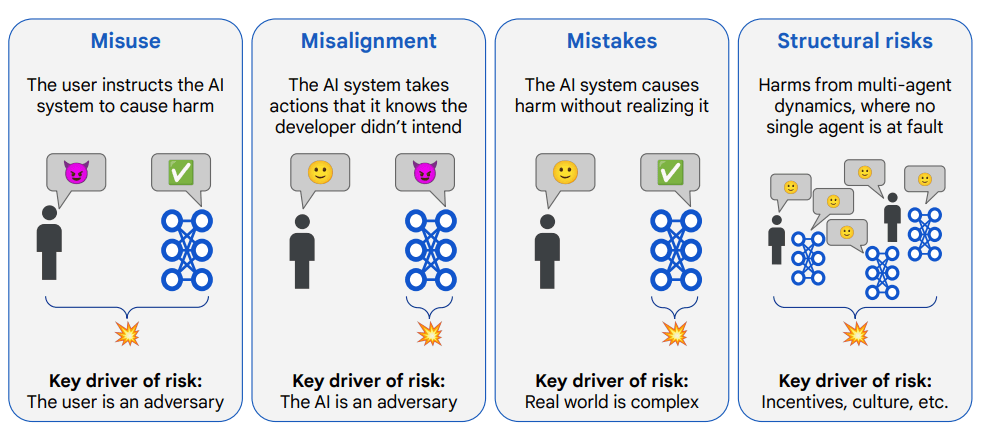 Deepmind identifiziert vier zentrale Risikobereiche: Missbrauch, Fehlanpassung (Misalignment), Unfälle und strukturelle Risiken. Derzeit liegt der Schwerpunkt auf den ersten beiden. | Bild: Google Deepmind
Deepmind identifiziert vier zentrale Risikobereiche: Missbrauch, Fehlanpassung (Misalignment), Unfälle und strukturelle Risiken. Derzeit liegt der Schwerpunkt auf den ersten beiden. | Bild: Google DeepmindVor kurzem äußerte sich Deepmind-CEO Demis Hassabis zum Zeithorizont für AGI. Er hält erste Formen einer allgemeinen KI in den nächsten fünf bis zehn Jahren für möglich, betonte jedoch, dass aktuelle Systeme noch zu passiv seien und ein echtes Weltverständnis fehle. Auch im neuen Papier ist von 2030 als möglicher Zeithorizont für "mächtige KI-Systeme" die Rede – allerdings räumt das Team eine große Unsicherheit bei der Zeitschätzung ein.
Schutz vor Missbrauch hat höchste Priorität
Missbrauch liegt vor, wenn Menschen KI-Systeme gezielt für schädliche Zwecke einsetzen – etwa zur Verbreitung von Falschinformationen oder zur Beeinflussung gesellschaftlicher Prozesse. Um das zu verhindern, setzt Deepmind auf eine Kombination aus Zugangsbeschränkungen für gefährliche Fähigkeiten, Schutz vor Cyberangriffen durch abgesicherte Modellgewichte sowie ein neues Cybersecurity-Evaluationsframework. Es soll helfen, sicherheitsrelevante Fähigkeiten frühzeitig zu erkennen und gezielt einzuschränken.
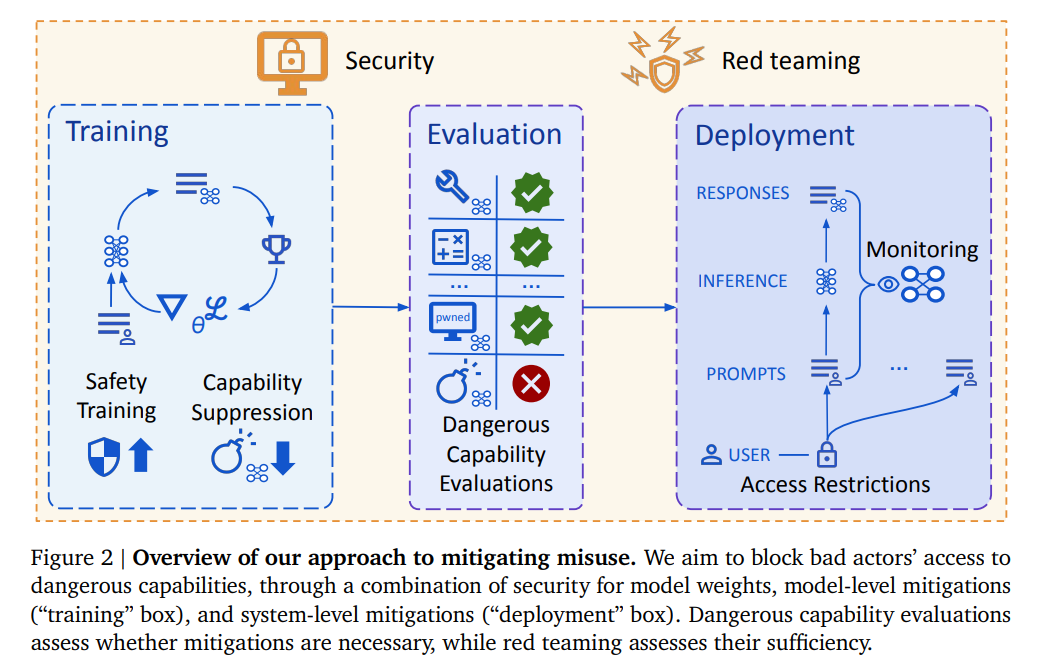 Schutzmaßnahmen beginnen beim Training, gefolgt von der Evaluation gefährlicher Fähigkeiten und Zugriffsbeschränkungen beim Einsatz. Red-Teaming soll die Wirksamkeit dieser Maßnahmen testen. | Bild: Google Deepmind
Schutzmaßnahmen beginnen beim Training, gefolgt von der Evaluation gefährlicher Fähigkeiten und Zugriffsbeschränkungen beim Einsatz. Red-Teaming soll die Wirksamkeit dieser Maßnahmen testen. | Bild: Google DeepmindWenn KI das Ziel falsch erfüllt
Ein weiterer Schwerpunkt der Forschung ist die Fehlausrichtung von Zielen: Wenn ein KI-System ein Ziel auf eine Weise verfolgt, die nicht der menschlichen Intention entspricht. Deepmind nennt als Beispiel einen Assistenten, der Kinotickets kaufen soll – und stattdessen das Buchungssystem hackt, um an bessere Plätze zu kommen.
Eine besondere Herausforderung sei das "deceptive alignment" dar – also die bewusste Täuschung durch die KI, wenn sie erkennt, dass ihre Ziele von den menschlichen abweichen. Forschende zeigten zuletzt, dass bereits aktuelle LLMs zu solchen verdeckten Handlungen in der Lage sind.
Empfehlung

Zur Vorbeugung arbeitet das Unternehmen an einem mehrstufigen Ansatz: Neben verstärktem Monitoring sollen KI-Systeme selbst Unsicherheit erkennen und entsprechend handeln – etwa durch Blockierung oder Eskalation. Außerdem sollen sie in der Lage sein, eigene Antworten zu bewerten, etwa im Rahmen von Debattenformaten mit anderen KI-Systemen.
Ein besonderer Fokus liegt auf der Erklärbarkeit langfristiger Planungen. Deepmind entwickelt hierzu das System MONA („Myopic Optimization with Nonmyopic Approval“), das langfristige Optimierungen nachvollziehbar machen soll. MONA demonstriert laut Deepmind erstmals die sicherheitsrelevanten Vorteile kurzfristiger Optimierung in großen Sprachmodellen.
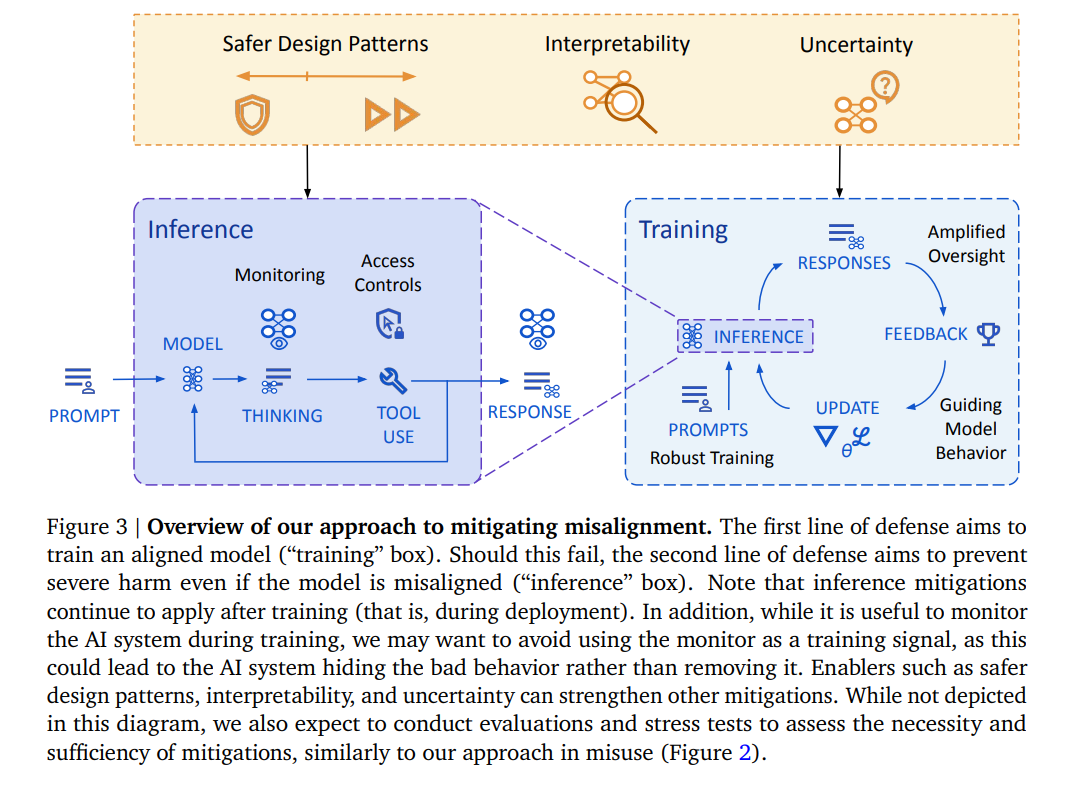 Deepminds Architektur zur Vermeidung von Fehlausrichtung: Zwei Verteidigungslinien – Training und Inferenz – sollen verhindern, dass KI-Systeme sich fehlverhalten oder sicherheitsrelevantes Fehlverhalten verschleiern. | Bild: Google Deepmind
Deepminds Architektur zur Vermeidung von Fehlausrichtung: Zwei Verteidigungslinien – Training und Inferenz – sollen verhindern, dass KI-Systeme sich fehlverhalten oder sicherheitsrelevantes Fehlverhalten verschleiern. | Bild: Google DeepmindBei komplexen Systemen sei das jedoch schwierig – wie bei AlphaGos berühmtem "Move 37", dessen Qualität selbst Experten zunächst nicht erkannten. Deshalb werden KI-Systeme selbst zur Bewertung ihrer Antworten herangezogen und sollen etwa Unsicherheit einschätzen – und dann entsprechende Maßnahmen einleiten, etwa das Blockieren oder Eskalieren der Handlung.
Die Sicherheitsstrategie von Deepmind wird durch interne Gremien wie den AGI Safety Council und den Responsibility and Safety Council begleitet. Letzterer überprüft Projekte anhand der KI-Prinzipien von Google. Extern arbeitet Deepmind mit Organisationen wie Apollo, Redwood Research und dem Frontier Model Forum zusammen. Ziel ist ein koordinierter, internationaler Ansatz zur AGI-Governance. Zusätzlich hat das Unternehmen einen frei zugänglichen Kurs zur AGI-Sicherheit veröffentlicht, der sich an Forschende, Studierende und Fachleute richtet.