Ein neuer Benchmark namens "CritPt" konfrontiert KI-Modelle mit physikalischer Forschung auf dem Niveau von Doktoranden. Die Ergebnisse zeigen, dass selbst führende KI-Modelle wie Gemini 3 Pro und GPT-5 weit davon entfernt sind, autonome Wissenschaftler zu sein.
Kann Künstliche Intelligenz Physikern helfen, echtes Neuland in der Spitzenforschung zu betreten? Um diese Frage zu beantworten, haben mehr als 50 Physiker von über 30 Institutionen weltweit den Benchmark "CritPt" (Complex Research using Integrated Thinking-Physics Test) entwickelt. Das Ziel ist ambitioniert: Die Modelle sollen nicht nur Lehrbuchwissen abrufen, sondern unveröffentlichte, realistische Forschungsaufgaben lösen.
Die ersten Ergebnisse sind hingegen ernüchternd und zeigen die Grenzen der aktuellen Technologie auf. Laut einer unabhängigen Auswertung von Artificial Analysis erreicht das derzeit leistungsfähigste Modell, Googles "Gemini 3 Pro Preview", lediglich eine Genauigkeit von 9,1 Prozent, und verwendete dabei noch zehn Prozent weniger Token als OpenAIs "GPT-5.1 (high)" mit 4,9 Prozent auf Platz zwei. Damit führt Google das Feld zwar deutlich an, scheitert aber dennoch am Großteil der Aufgaben.
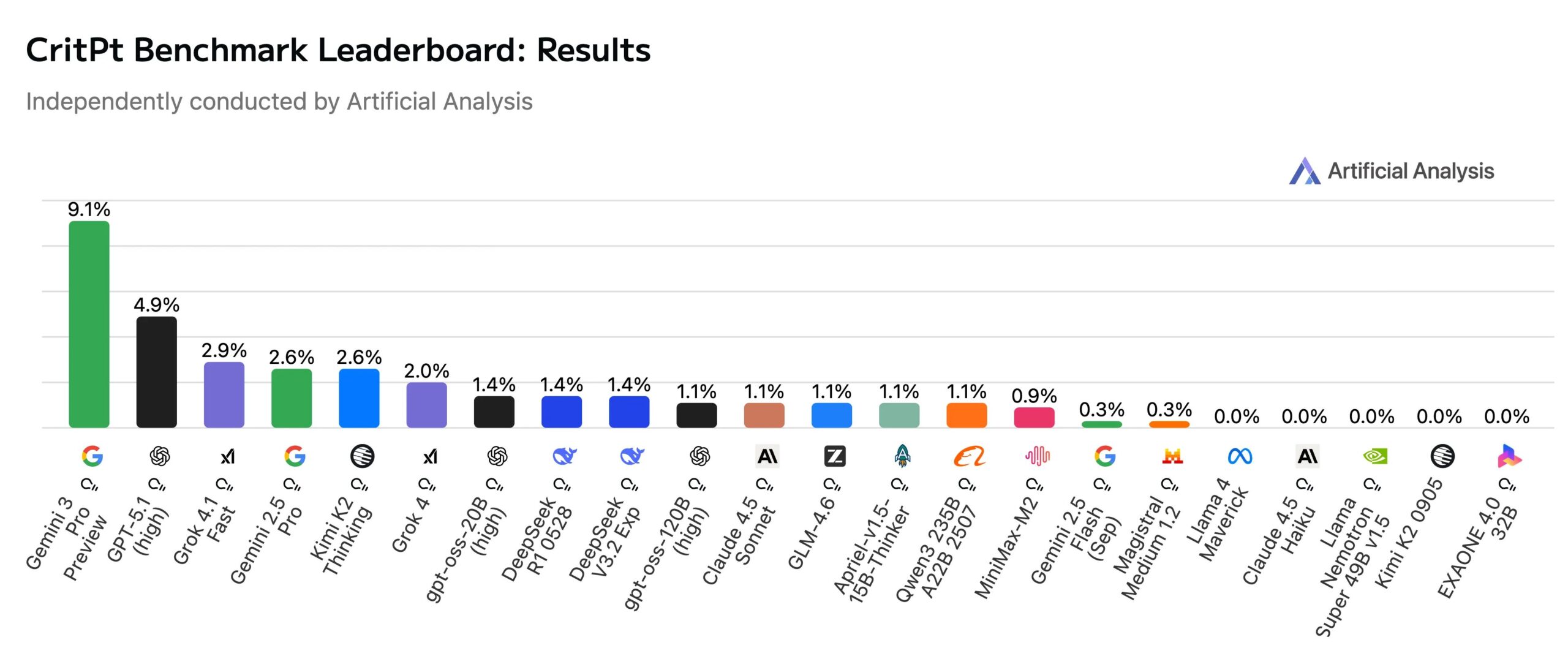 Unabhängige Auswertung von Artificial Analysis: Selbst kommende Modelle lösen kaum 10 Prozent der Aufgaben. | Bild: Artificial Analysis
Unabhängige Auswertung von Artificial Analysis: Selbst kommende Modelle lösen kaum 10 Prozent der Aufgaben. | Bild: Artificial AnalysisDoktoranden-Niveau als Hürde
Der CritPt-Benchmark umfasst 71 komplexe Forschungsherausforderungen aus elf physikalischen Disziplinen, darunter Quantenphysik, Astrophysik, Hochenergiephysik und Biophysik. Die Aufgaben sind so konzipiert, dass sie dem Niveau eines fähigen Doktoranden (Junior PhD Student) entsprechen, der ein eigenständiges Projekt bearbeitet. Um "Googeln" oder Raten zu verhindern, basieren die Tests auf unveröffentlichtem Material.
Die Forscher unterteilten die großen Herausforderungen zudem in 190 modulare "Checkpoints", um auch Teilerfolge messbar zu machen. Doch das Fazit der Physiker fällt deutlich aus: Heutige LLMs sind weit davon entfernt, die integrierte Strenge, Kreativität und Präzision zu besitzen, die für die unabhängige Lösung offener physikalischer Forschungsprobleme erforderlich sind.
Trotz der niedrigen Erfolgsquoten sehen die Autoren Potenzial auf der Ebene der einfacheren "Checkpoints", also gut abgegrenzter Teilaufgaben. Hier zeigten die Modelle messbare Fortschritte.
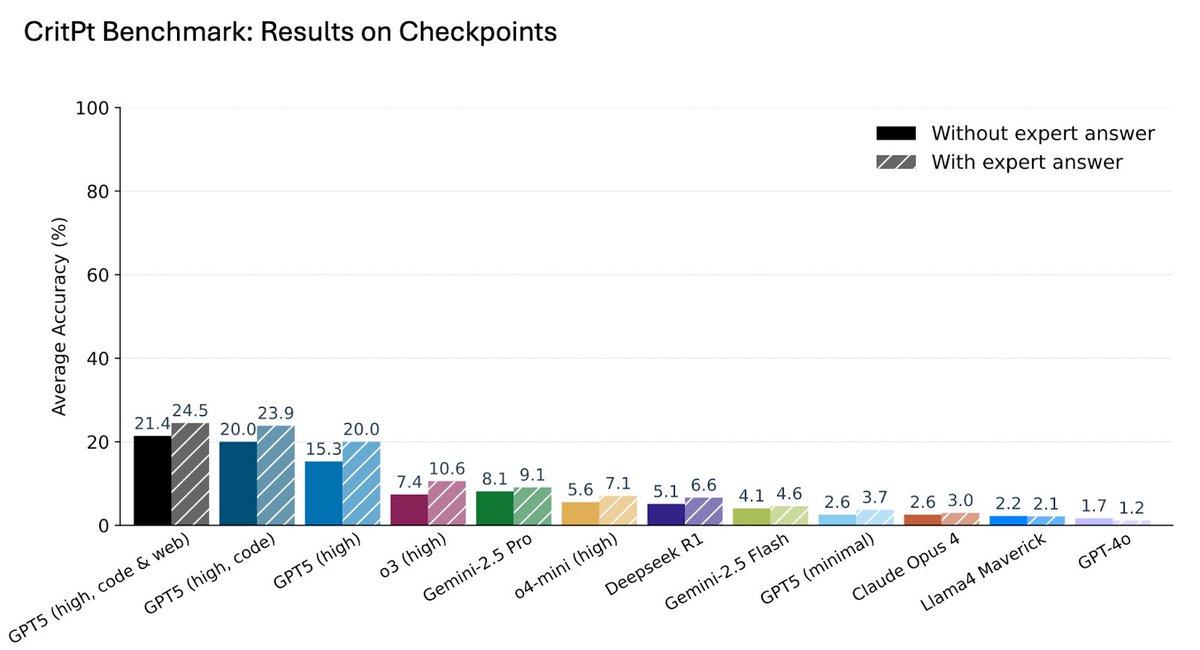 Bei den einfacheren "Checkpoints" (Teilaufgaben) schneiden die Modelle deutlich besser ab als bei den kompletten Forschungsherausforderungen. | | Bild: Zhu et al.
Bei den einfacheren "Checkpoints" (Teilaufgaben) schneiden die Modelle deutlich besser ab als bei den kompletten Forschungsherausforderungen. | | Bild: Zhu et al.Die Vision für die kommende Zeit sei daher nicht der "KI-Wissenschaftler", der menschliche Forscher ersetzt, sondern der "Forschungsassistent", der Teilaufgaben automatisiert. Eine Partnerschaft zwischen Physik und KI sei notwendig, um wissenschaftlich fundierte KI-Werkzeuge zu entwickeln.
OpenAI hat sich zum Ziel gesetzt, bis September 2026 erstmals einen Forschungspraktikanten auf den Markt zu bringen. Spätestens im März 2028 soll ein vollständig autonomer KI-Forscher folgen. Das kürzlich veröffentlichte GPT-5 soll laut einer Studie des Unternehmens Forschern und Forscherinnen bereits Zeit sparen.
Mangelnde Robustheit bei komplexen Aufgaben
Ein weiteres Problem ist die Verlässlichkeit. Das Team führte die Metrik der "konsistenten Lösungsrate" ein. Um diesen Wert zu erreichen, muss ein Modell eine Aufgabe in vier von fünf Versuchen korrekt lösen.
Unter dieser strengeren Bedingung bricht die Leistung der Modelle noch weiter ein. Das offenbart eine mangelnde Robustheit: Die Erfolgsquote bricht stark ein, selbst bei Aufgaben, die die Modelle grundsätzlich lösen können.
 Die "Consistently Solved Rate" (rechts) zeigt, dass die Modelle oft nicht robust sind: Die Leistung bricht ein, wenn eine korrekte Antwort in 4 von 5 Fällen gefordert wird. Gemini 3 Pro fehlt in dieser Untersuchung noch. | Bild: Zhu et al.
Die "Consistently Solved Rate" (rechts) zeigt, dass die Modelle oft nicht robust sind: Die Leistung bricht ein, wenn eine korrekte Antwort in 4 von 5 Fällen gefordert wird. Gemini 3 Pro fehlt in dieser Untersuchung noch. | Bild: Zhu et al.Die Gefahr dabei ist subtil: Die Modelle generieren oft plausible Antworten, die jedoch kleine, schwer zu identifizierende Fehler enthalten. In einem komplexen Forschungskontext können solche Fehler irreführend sein und erfordern eine umfangreiche Überprüfung durch Experten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar“‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.


