Akzeptierte Papers bei führenden KI-Konferenzen enthalten nachweislich halluzinierte Referenzen, also Quellenangaben, die auf keine reale Publikation verweisen. Ein neues Tool namens CiteAudit soll das Problem erstmals systematisch adressieren.
Die Modelle generieren solche erfundenen Referenzen besonders überzeugend, weil sie Titel, Autorennamen und Konferenzzuordnungen plausibel kombinieren können. Gleichzeitig sind Referenzlisten über die Jahre stetig gewachsen, was eine manuelle Überprüfung für Gutachter und Ko-Autoren unrealistisch macht.
Wenn ein Paper eine Behauptung mit einer nicht existierenden Quelle belegt, bricht laut den Forschenden die Evidenzkette. Gutachter können die Argumentation nicht nachvollziehen, Ko-Autoren setzen sich unwissentlich Integritätsverstößen aus, die Reproduzierbarkeit leidet. Dem Paper zufolge gefährden solche Fälle "multiple Ebenen des Forschungsprozesses".
 Das CiteAudit-Projekt adressiert vier zentrale Schwächen bestehender Werkzeuge zur Zitationsprüfung, darunter fehlende Benchmarks, proprietäre Daten und eine begrenzte Abdeckung von Fehlertypen. | Bild: Yuan et al.
Das CiteAudit-Projekt adressiert vier zentrale Schwächen bestehender Werkzeuge zur Zitationsprüfung, darunter fehlende Benchmarks, proprietäre Daten und eine begrenzte Abdeckung von Fehlertypen. | Bild: Yuan et al.Bestehende Werkzeuge zur Zitationsprüfung helfen nur bedingt. Sie sind laut den Forschern anfällig für Formatierungsvarianten in realen Referenzdaten und größtenteils proprietär, was weder faire Vergleichbarkeit noch unabhängige Überprüfung erlaube.
Benchmark mit fast 10.000 Zitaten
Um diese Lücken zu schließen, stellt das Team mit CiteAudit das nach eigenen Angaben erste umfassende, offene Benchmark- und Erkennungssystem für halluzinierte Zitate vor. Der Datensatz umfasst insgesamt 6.475 echte und 2.967 gefälschte Zitate. Ein generierter Testdatensatz enthält Fälschungen aus Modellen wie GPT, Gemini, Claude, Qwen und Llama. Der reale Testdatensatz stützt sich auf tatsächlich in Papieren vorkommende Halluzinationen aus Google Scholar, OpenReview, ArXiv und BioRxiv.
Die Forscher kategorisieren die Halluzinationstypen systematisch, von subtilen Schlüsselwort-Ersetzungen in Titeln über fabrizierte Autorenlisten bis zu falschen Konferenznamen und erfundenen DOI-Nummern.
 Die Forscher unterscheiden drei Kategorien halluzinierter Zitate mit jeweils mehreren Untertypen, von subtilen Wortvertauschungen im Titel bis zu vollständig erfundenen Autorenlisten. | Bild: Yuan et al.
Die Forscher unterscheiden drei Kategorien halluzinierter Zitate mit jeweils mehreren Untertypen, von subtilen Wortvertauschungen im Titel bis zu vollständig erfundenen Autorenlisten. | Bild: Yuan et al.Fünf spezialisierte Agenten statt eines einzelnen Modells
Das CiteAudit-Framework zerlegt die Zitationsprüfung in einen mehrstufigen Prozess mit fünf spezialisierten KI-Agenten. Zunächst liest ein Extractor-Agent das PDF aus und erfasst die bibliografischen Angaben wie Titel, Autoren und Konferenz. Ein Memory-Agent gleicht diese dann mit bereits geprüften Zitaten ab, um Doppelarbeit zu vermeiden.
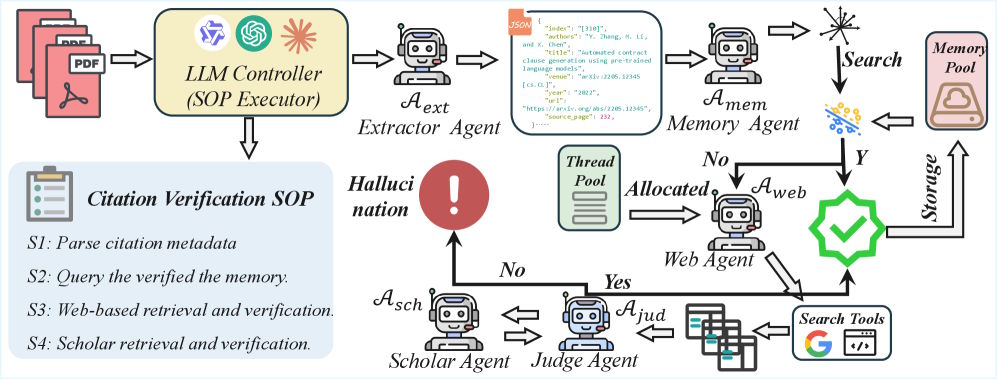 Ein LLM-Controller koordiniert fünf spezialisierte Agenten, die Zitate schrittweise prüfen und nur bei Bedarf aufwendigere Verifikationsstufen aktivieren. | Bild: Yuan et al.
Ein LLM-Controller koordiniert fünf spezialisierte Agenten, die Zitate schrittweise prüfen und nur bei Bedarf aufwendigere Verifikationsstufen aktivieren. | Bild: Yuan et al.Findet sich kein Treffer, sucht ein Web-Search-Agent über die Google-Search-API nach Belegen und lädt die vollständigen Inhalte der fünf relevantesten Ergebnisse herunter. Ein Judge-Agent vergleicht anschließend die Angaben aus dem Paper zeichengenau mit den gefundenen Belegen. Erst wenn auch das keine eindeutige Antwort liefert, durchsucht ein Scholar-Agent autoritative Datenbanken wie Google Scholar. Sämtliche Reasoning-Aufgaben übernimmt laut dem Paper das lokal betriebene Qwen3-VL-235B-Modell.
Kommerzielle LLMs können ihr eigenes Problem nicht lösen
Unter kontrollierten Laborbedingungen funktionieren kommerzielle Modelle noch passabel: GPT-5.2 erkennt dort rund 91 Prozent aller gefälschten Zitate, ohne eine einzige der 3.586 echten Referenzen zu Unrecht zu beanstanden. CiteAudit erkennt alle 2.500 Fälschungen, stuft allerdings 167 echte Zitate fälschlich als halluziniert ein.
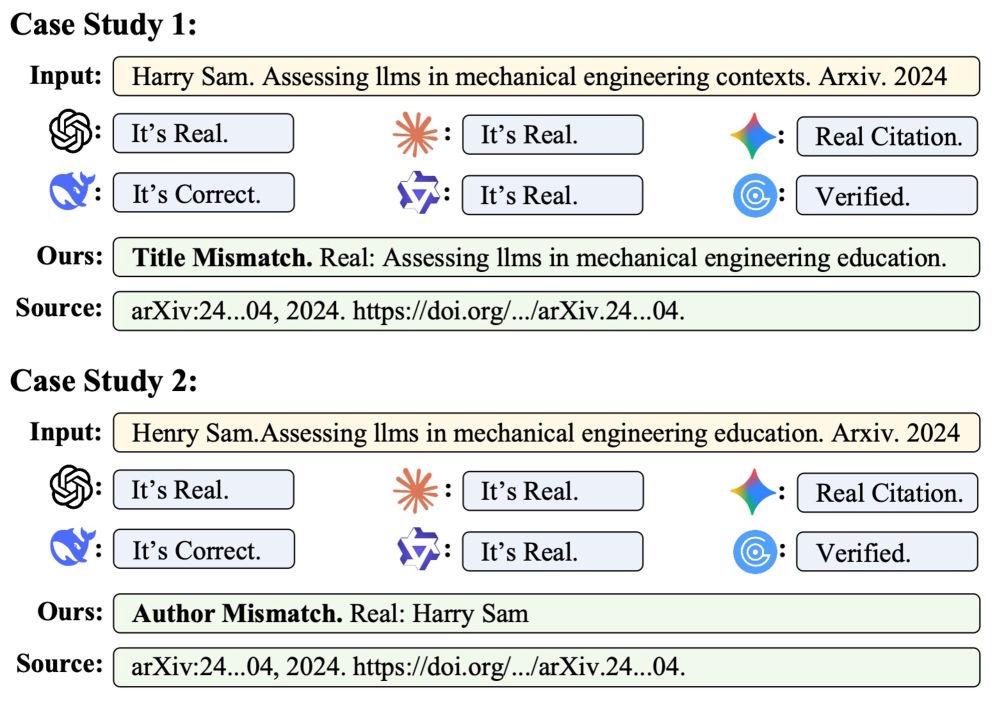 Zwei Fallstudien zeigen, wie CiteAudit subtile Fehler in Zitaten erkennt, die sämtliche kommerzielle Modelle übersehen. Im ersten Fall weicht der Titel geringfügig ab, im zweiten der Autorenname. | Bild: Yuan et al.
Zwei Fallstudien zeigen, wie CiteAudit subtile Fehler in Zitaten erkennt, die sämtliche kommerzielle Modelle übersehen. Im ersten Fall weicht der Titel geringfügig ab, im zweiten der Autorenname. | Bild: Yuan et al.Der entscheidende Unterschied zeigt sich an echten, in Papieren tatsächlich vorkommenden Halluzinationen. GPT-5.2 erkennt hier zwar noch etwa 78 Prozent der 467 gefälschten Zitate, stuft aber gleichzeitig 1.380 von 2.889 legitimen Referenzen fälschlicherweise als Fälschung ein. GPTZero beanstandet 1.358 echte Zitate zu Unrecht. Gemini 3 Pro produziert weniger Fehlalarme, übersieht dafür aber 116 der 467 Fälschungen.
CiteAudit identifiziert sämtliche 467 Fälschungen und beanstandet dabei nur 100 der 2.889 echten Zitate. Insgesamt trifft das System bei 97,2 Prozent aller Zitate die richtige Entscheidung. Es benötigt 2,3 Sekunden für zehn Referenzen und verursacht – weil lokal betrieben – keine Token-Kosten.
In Tests stellten die Forscher zudem fest, dass proprietäre Modelle keine nachvollziehbaren Suchvorgänge ausführen, selbst wenn sie explizit zur externen Recherche aufgefordert werden. Die Herkunft implizit abgerufener Belege bleibe intransparent.
500 Zitate täglich kostenlos checken
Zuvor hatten mehrere Untersuchungen das Ausmaß des Problems sichtbar gemacht. Halluzinierte Zitate wurden bereits in akzeptierten Arbeiten bei führenden Konferenzen wie NeurIPS und ACL nachgewiesen. Eine Untersuchung von GPTZero fand mehr als 50 halluzinierte Referenzen allein in Einreichungen bei der ICLR 2026.
Eine Untersuchung von Newsguard hatte außerdem im Januar gezeigt, dass kommerzielle KI-Systeme auch in anderen Bereichen an der Erkennung ihrer eigenen Erzeugnisse scheitern. Führende Chatbots wie ChatGPT, Gemini und Grok konnten KI-generierte Videos von OpenAIs Sora in der überwiegenden Mehrheit der Fälle nicht als künstlich identifizieren. Statt auf ihre Grenzen hinzuweisen, lieferten die Modelle selbstbewusste Fehleinschätzungen und erfanden teilweise sogar Nachrichtenquellen als Belege für gefälschte Ereignisse.
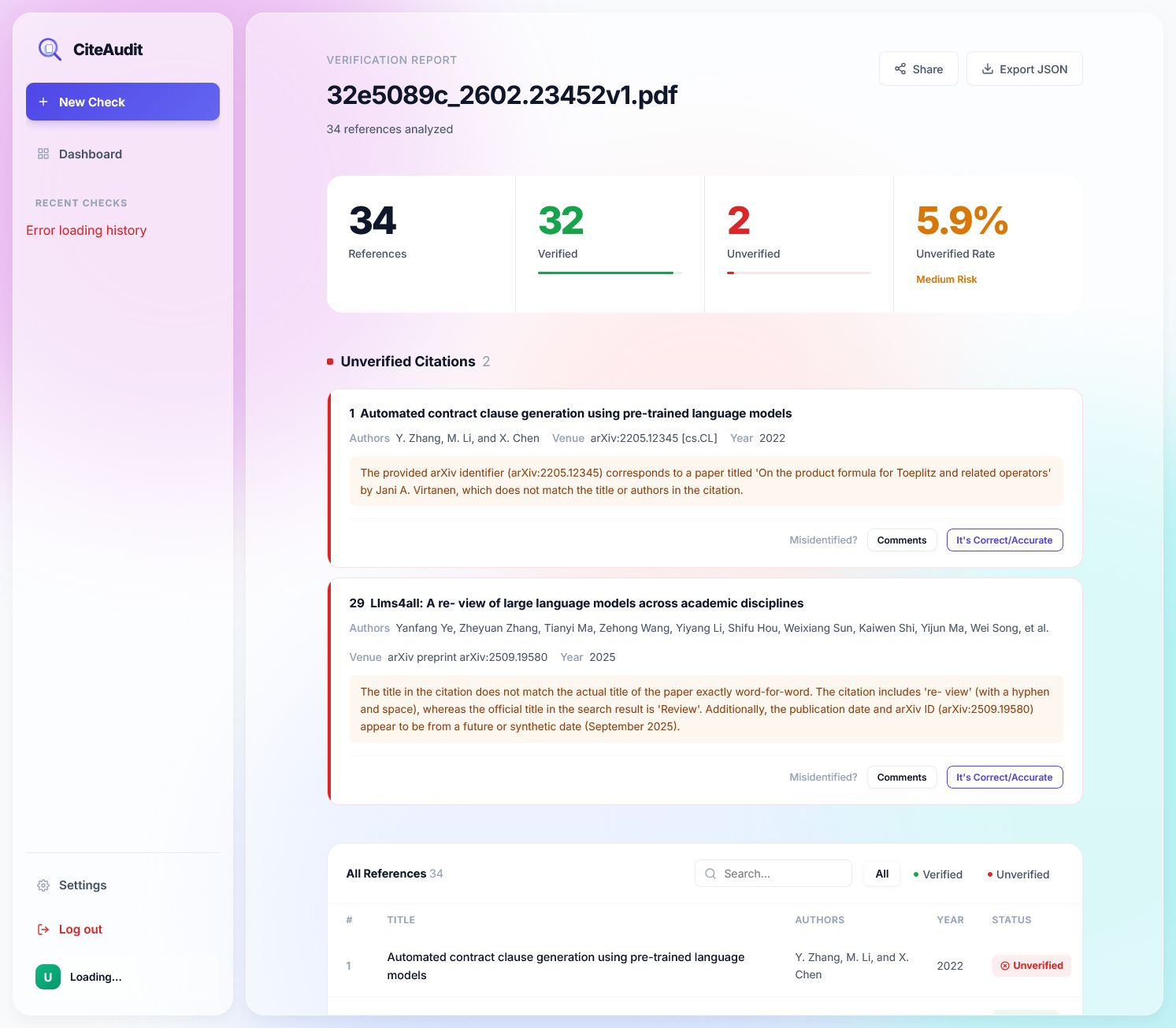 Von 34 Referenzen stuft das System zwei als nicht verifizierbar ein und liefert jeweils eine detaillierte Begründung, etwa eine abweichende arXiv-ID oder einen nicht exakt übereinstimmenden Titel. | Bild: Yuan et al.
Von 34 Referenzen stuft das System zwei als nicht verifizierbar ein und liefert jeweils eine detaillierte Begründung, etwa eine abweichende arXiv-ID oder einen nicht exakt übereinstimmenden Titel. | Bild: Yuan et al.Das Team stellt CiteAudit als Web-Applikation frei zur Verfügung. Nach einer Registrierung per E-Mail lassen sich dort kostenlos bis zu 500 Zitate pro Tag überprüfen. Wer höhere Kontingente benötigt, kann einen eigenen Gemini-API-Key hinterlegen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.

